Parallelize speculative decoding with P-EAGLE on Amazon SageMaker
💡Learn how to reduce LLM inference latency using P-EAGLE parallel speculative decoding on Amazon SageMaker.
⚡ 30-Second TL;DR
What Changed
Integrates P-EAGLE for parallelized speculative decoding on SageMaker AI.
Why It Matters
This integration significantly reduces latency for real-time generative AI applications by optimizing the drafting process in speculative decoding. It lowers the barrier for developers to implement advanced inference acceleration techniques on managed infrastructure.
What To Do Next
Deploy a compatible model from SageMaker JumpStart using P-EAGLE to benchmark latency improvements for your specific LLM workload.
🧠 Deep Insight
Web-grounded analysis with 25 cited sources.
🔑 Enhanced Key Takeaways
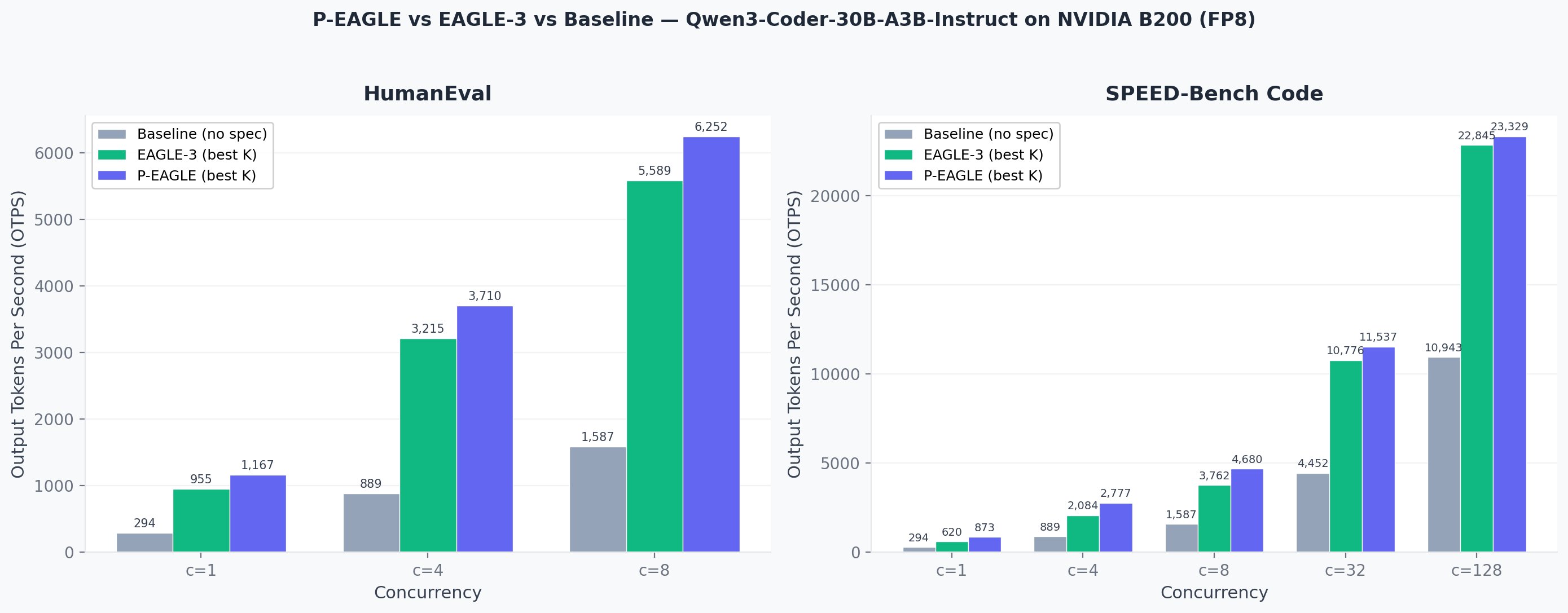
- •P-EAGLE eliminates the sequential bottleneck of traditional speculative decoding by generating all K draft tokens in a single parallel forward pass, achieving up to 1.69x speedup over vanilla EAGLE-3 on NVIDIA B200 GPUs and 4-5x speedup over standard decoding on coding benchmarks.
- •This parallelization is enabled by using learnable mask tokens and a shared hidden state to substitute for missing information at Multi-Token Prediction (MTP) positions, allowing simultaneous prediction of multiple future tokens.
- •The P-EAGLE method includes a scalable training framework that features attention mask pre-computation and sequence partitioning, making it practical to train drafters on long contexts (up to 20K tokens) required by reasoning LLMs.
- •AWS has open-sourced P-EAGLE and integrated it into vLLM (v0.16.0+), with pre-trained P-EAGLE heads available on HuggingFace for models like GPT-OSS 120B, GPT-OSS 20B, and Qwen3-Coder 30B, simplifying adoption.
- •The integration into Amazon SageMaker AI, particularly via SageMaker JumpStart, provides a managed service offering for deploying these highly optimized real-time endpoints, abstracting away much of the underlying infrastructure complexity for developers.
📊 Competitor Analysis▸ Show
| Feature / Platform | AWS SageMaker AI | Google Cloud Vertex AI | Microsoft Azure ML | vLLM (Open-Source) | NVIDIA TensorRT-LLM |
|---|---|---|---|---|---|
| Type | Managed ML Platform | Managed ML Platform | Managed ML Platform | LLM Inference Library | LLM Inference Library |
| Speculative Decoding Support | Yes (P-EAGLE integrated) | Yes (used in Google products like Search AI Overviews) | General LLM inference support, specific parallel SD not detailed | Yes (P-EAGLE integrated, widely adopted) | Yes (supports speculative decoding) |
| Ease of Deployment | JumpStart for optimized endpoints | Integrated suite, AutoML capabilities | Drag-and-drop, Azure ecosystem integration | Requires self-hosting/integration into serving stack | Requires integration into serving stack |
| Hardware Focus | AWS instances (e.g., Inferentia2, Trainium, NVIDIA GPUs) | Google Cloud (CPUs, GPUs, TPUs) | Azure (CPUs, GPUs) | GPU-agnostic (often NVIDIA) | NVIDIA GPUs (optimized for) |
| Key Differentiator | Fully managed, broad ML services, JumpStart catalog | End-to-end ML suite, strong AutoML, TPU support | Enterprise MLOps, Azure ecosystem integration | High-throughput, low-latency serving for LLMs, open-source | Deep optimization for NVIDIA hardware, inference acceleration |
| Pricing Model | Per-instance/usage, managed service overhead | Per-resource/usage | Per-resource/usage | Free (open-source), infrastructure costs | Free (library), infrastructure costs |
🛠️ Technical Deep Dive
- Speculative Decoding Core: This inference optimization technique pairs a larger, high-quality target model with a smaller, faster draft mechanism. The draft model proposes multiple candidate tokens, which the target model then verifies in parallel in a single forward pass, accepting the longest prefix that matches its own predictions.
- EAGLE's Evolution: The Extrapolation Algorithm for Greater Language-Model Efficiency (EAGLE) is a speculative decoding method that operates at the feature level, extrapolating from the hidden state just before the target model's output head. This approach eliminates the need for a separate draft model. EAGLE-3, a later iteration, improved upon this by predicting tokens directly rather than intermediate features and by leveraging representations from multiple layers of the target model to boost draft accuracy.
- P-EAGLE's Innovation: P-EAGLE transforms the autoregressive draft generation of previous EAGLE versions into a parallel process. Instead of requiring K sequential forward passes through the draft head to propose K tokens, P-EAGLE generates all K draft tokens simultaneously in a single forward pass.
- Mechanism for Parallel Drafting: To enable parallel prediction, P-EAGLE addresses the challenge of missing hidden vectors and previous tokens for subsequent predictions. It uses two learnable parameters: a shared hidden state (
h_shared) that substitutes for missing hidden vectors and a mask token embedding that substitutes for unknown previous tokens at Multi-Token Prediction (MTP) positions. - Scalable Training Framework: P-EAGLE includes a scalable training framework designed for long contexts, which is critical for reasoning LLMs that produce extended outputs. This framework features attention mask pre-computation and a sequence partition algorithm for intra-sequence splitting, enabling gradient accumulation within individual sequences for parallel-prediction training.
- Integration and Optimization: P-EAGLE is integrated into the vLLM inference engine (starting from v0.16.0) and utilizes hand-written fused Triton kernels to minimize overhead associated with batch metadata rebuilds, further enhancing its performance.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (25)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗