⚛️量子位•Freshcollected in 55m
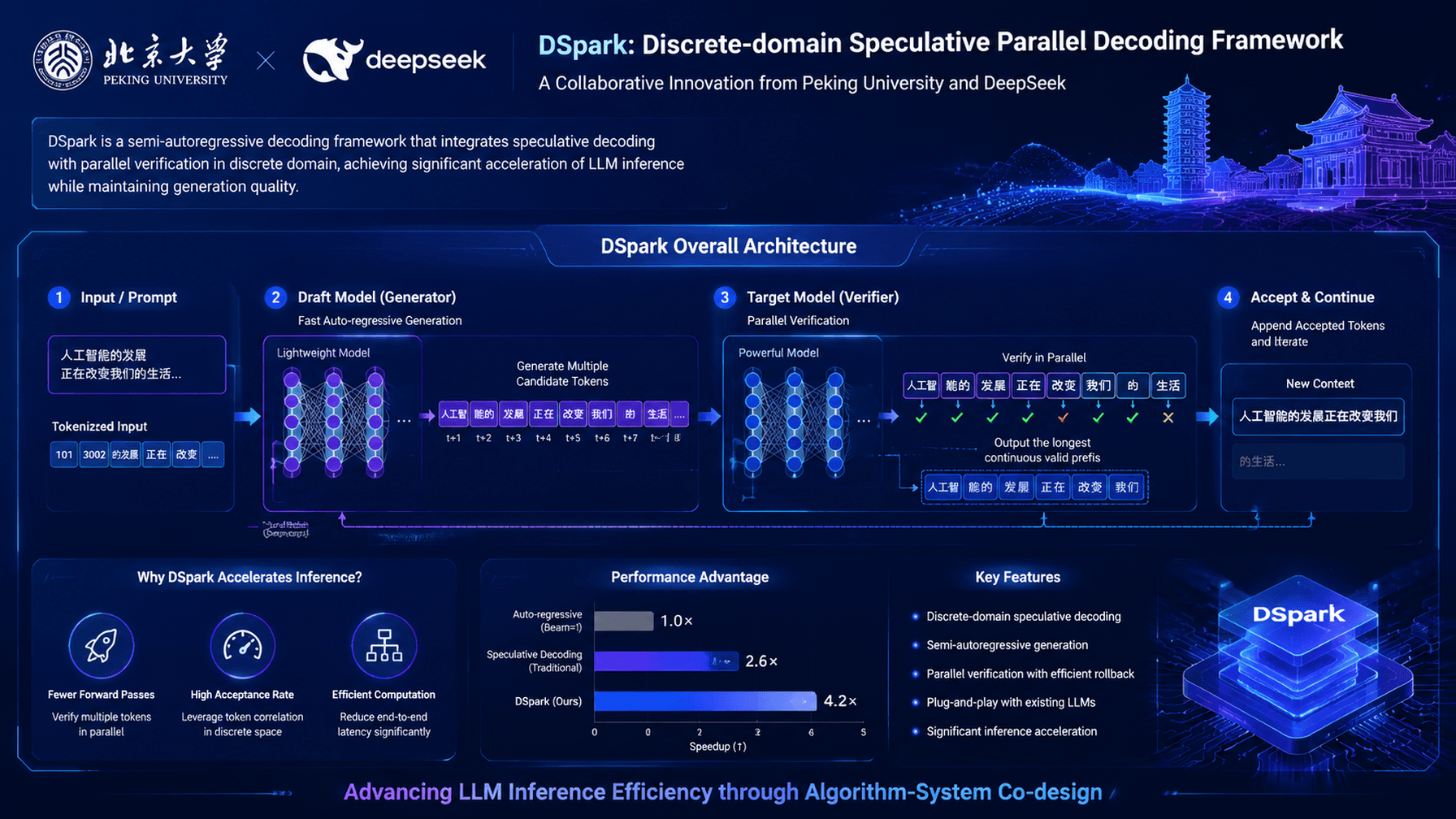
Understanding Liang Wenfeng's DSpark in 10 points
💡Learn how top-tier system engineering can solve production-level AI bottlenecks.
⚡ 30-Second TL;DR
What Changed
Focuses on high-performance system engineering architecture
Why It Matters
This project could redefine how developers approach the integration of AI models into production-grade systems.
What To Do Next
Review the DSpark repository architecture to identify patterns for optimizing your own inference pipeline.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Liang Wenfeng is the founder of DeepWisdom (Jiuzhang), a company previously known for its focus on AutoML and automated AI development platforms.
- •DSpark represents a strategic pivot or expansion from Liang's previous work, moving from automated model generation toward underlying AI infrastructure and system-level optimization.
- •The project specifically targets the 'memory wall' and interconnect bottlenecks prevalent in training massive parameter models on heterogeneous GPU clusters.
- •DSpark integrates proprietary scheduling algorithms designed to improve GPU utilization rates by reducing idle time during data-parallel and model-parallel synchronization.
- •The framework is positioned as a middleware layer that sits between the orchestration layer (like Kubernetes) and the deep learning framework (like PyTorch or JAX) to provide hardware-aware optimization.
📊 Competitor Analysis▸ Show
| Feature | DSpark | NVIDIA Triton | DeepSpeed |
|---|---|---|---|
| Primary Focus | System-level AI Infrastructure | Inference Serving | Training Optimization |
| Pricing | Proprietary/Enterprise | Open Source | Open Source |
| Benchmarks | Focus on GPU Utilization | Latency/Throughput | Memory Efficiency |
🛠️ Technical Deep Dive
- Implements a custom memory management layer that bypasses standard OS-level paging to reduce latency in large-scale tensor operations.
- Utilizes a graph-based execution engine that dynamically reorders compute kernels to maximize cache locality on NVIDIA H100/B200 architectures.
- Features a distributed communication backend optimized for high-bandwidth interconnects like NVLink and InfiniBand, minimizing collective communication overhead.
- Supports heterogeneous hardware abstraction, allowing seamless switching between different GPU architectures without modifying the underlying model code.
🔮 Future ImplicationsAI analysis grounded in cited sources
DSpark will become a critical component for domestic AI infrastructure in China.
The focus on optimizing heterogeneous hardware aligns with the industry trend of utilizing diverse, non-NVIDIA GPU clusters due to export restrictions.
DeepWisdom will transition its business model toward infrastructure-as-a-service (IaaS) optimization.
The shift from AutoML to system-level engineering suggests a move toward selling performance-enhancing middleware rather than just model-building tools.
⏳ Timeline
2017-01
Liang Wenfeng founds DeepWisdom (Jiuzhang) focusing on AutoML.
2021-05
DeepWisdom completes a significant Series B funding round to scale AI automation.
2025-11
Initial internal development of DSpark infrastructure begins.
2026-04
Liang Wenfeng publicly introduces the DSpark framework concept.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: 量子位 ↗