DeepSeek launches DSpark to boost inference speed by 85%

💡Learn how DeepSeek's new DSpark framework achieves an 85% speed boost to cut inference costs.
⚡ 30-Second TL;DR
What Changed
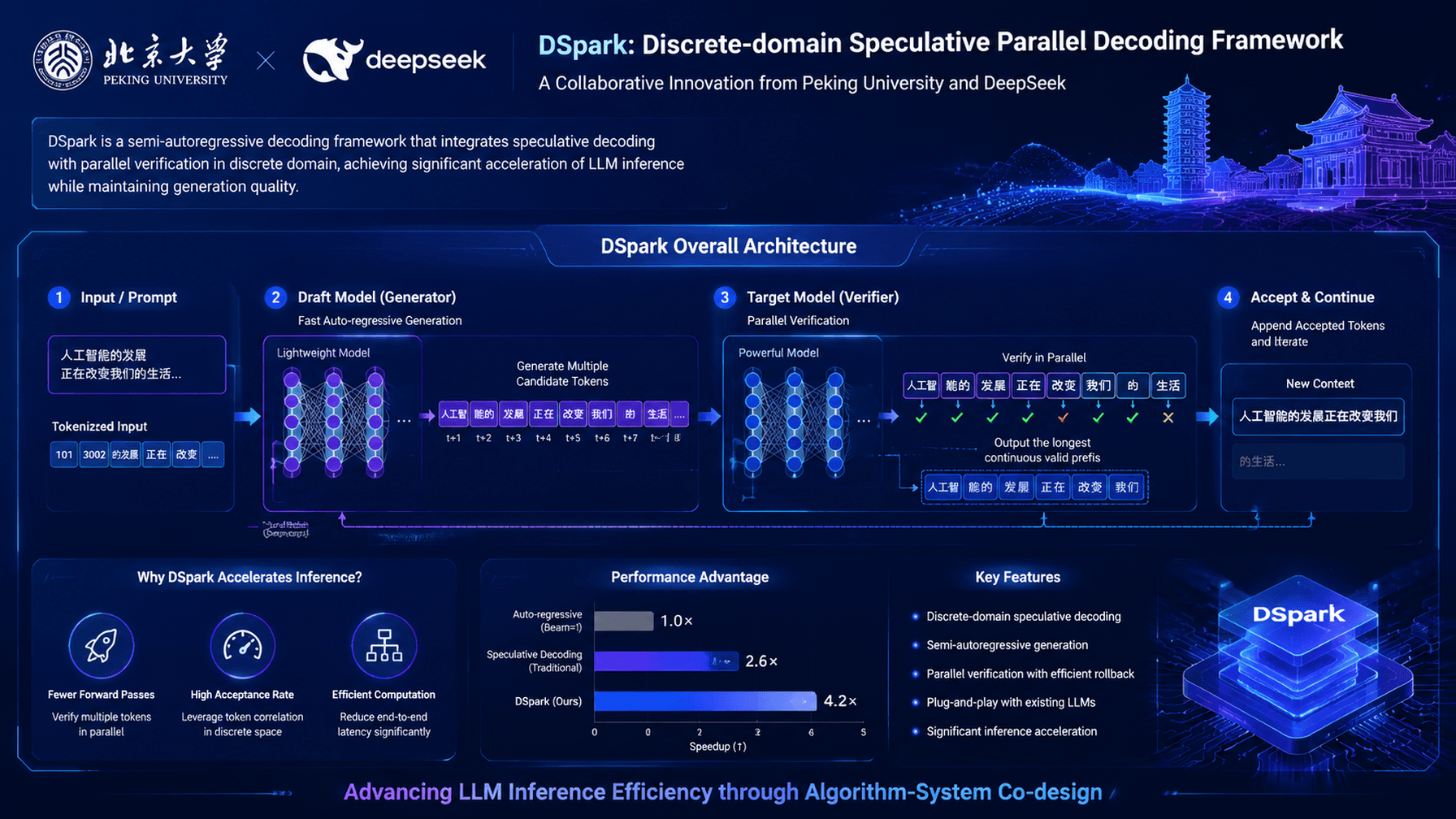
DeepSeek V4 model integrated with DSpark speculative decoding framework.
Why It Matters
This development highlights the growing importance of speculative decoding in making large-scale LLM deployment economically viable. It provides a blueprint for developers to optimize inference throughput without requiring additional GPU resources.
What To Do Next
Evaluate speculative decoding frameworks like DSpark to optimize your current LLM inference pipeline and reduce operational latency.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •DSpark utilizes a lightweight 'draft model' architecture that predicts multiple tokens simultaneously before verifying them against the primary V4 model.
- •The framework is specifically optimized for DeepSeek's proprietary hardware clusters, leveraging custom kernels to minimize memory bandwidth overhead during the verification phase.
- •DeepSeek has open-sourced the core components of DSpark, encouraging adoption within the broader Chinese AI ecosystem to standardize inference optimization practices.
- •The 85% speed improvement is most pronounced in long-context scenarios where the draft model's high acceptance rate significantly reduces the number of full-model forward passes.
- •DSpark includes a dynamic threshold adjustment mechanism that automatically scales the draft model's aggressiveness based on real-time GPU utilization and request latency.
📊 Competitor Analysis▸ Show
| Feature | DeepSeek DSpark | NVIDIA TensorRT-LLM | Groq LPU Inference |
|---|---|---|---|
| Primary Focus | Speculative Decoding | Kernel Optimization | Hardware Acceleration |
| Pricing | Open Source/Integrated | Open Source | Proprietary Cloud API |
| Benchmarks | Up to 85% speedup | Varies by hardware | Ultra-low latency (sub-ms) |
🛠️ Technical Deep Dive
- Architecture: Implements a multi-token speculative decoding pipeline where a small draft model generates a sequence of tokens that are validated in parallel by the V4 model.
- Memory Management: Utilizes KV-cache quantization to reduce the memory footprint of the draft model, allowing it to reside entirely in SRAM for faster access.
- Verification Logic: Employs a custom rejection sampling algorithm that balances token acceptance rates with the computational cost of the draft model.
- Hardware Integration: Optimized for high-bandwidth memory (HBM) architectures, reducing the latency penalty typically associated with transferring draft tokens to the main model.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📰 Event Coverage
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: SCMP Technology ↗