Peking University and DeepSeek Open-Source DSpark Inference Framework
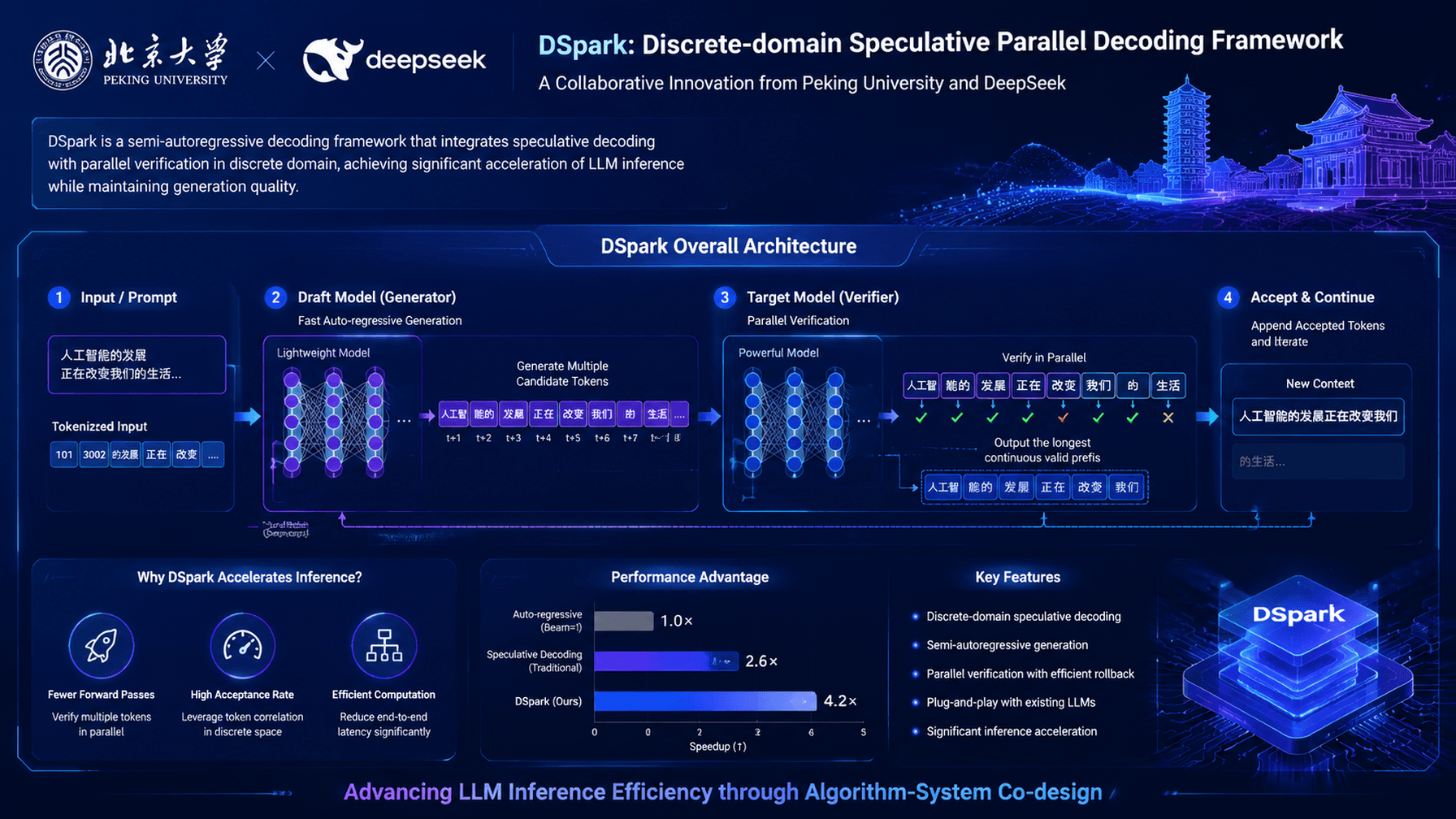
💡New open-source speculative decoding framework from DeepSeek that boosts LLM inference throughput by up to 661%.
⚡ 30-Second TL;DR
What Changed
Boosts LLM inference speed by 60-85% using speculative decoding
Why It Matters
DSpark provides a powerful tool for developers looking to optimize LLM deployment costs and latency. This could significantly lower the barrier for running high-performance models in production environments.
What To Do Next
Clone the DSpark repository and benchmark it against your current inference engine to see if it meets your latency requirements.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •DSpark utilizes a novel 'tree-based' speculative decoding mechanism that optimizes the verification process for multi-token prediction.
- •The framework is specifically engineered to address the memory bandwidth bottleneck common in autoregressive LLM inference by reducing the number of sequential memory accesses.
- •DSpark integrates seamlessly with existing DeepSeek model architectures, leveraging their specific weight distributions to improve draft model accuracy.
- •The open-source release includes specialized kernels optimized for NVIDIA GPU architectures to minimize overhead during the speculative verification phase.
- •Research indicates that DSpark's performance gains are most pronounced in long-context scenarios where the draft model can effectively predict subsequent tokens.
📊 Competitor Analysis▸ Show
| Feature | DSpark | Medusa | Speculative Decoding (Standard) |
|---|---|---|---|
| Architecture | Tree-based Speculative | Multi-head Attention | Standard Draft Model |
| Throughput Gain | Up to 661% | ~200-300% | ~150-200% |
| Latency Optimization | High (Strict) | Medium | Low |
| Open Source | Yes | Yes | Yes |
🛠️ Technical Deep Dive
- Implements a tree-based speculative decoding strategy that allows for the parallel verification of multiple candidate token sequences.
- Utilizes a lightweight draft model to generate token trees, which are then validated by the target LLM in a single forward pass.
- Employs custom CUDA kernels to reduce the latency of the tree-verification step, which is often the bottleneck in standard speculative decoding.
- Optimizes memory access patterns to maximize the utilization of GPU Tensor Cores during the verification phase.
- Supports dynamic batching to maintain high throughput even when multiple inference requests are processed concurrently.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗