🐯虎嗅•Freshcollected in 86m
Reflections on the AI era: Infrastructure and Profitability
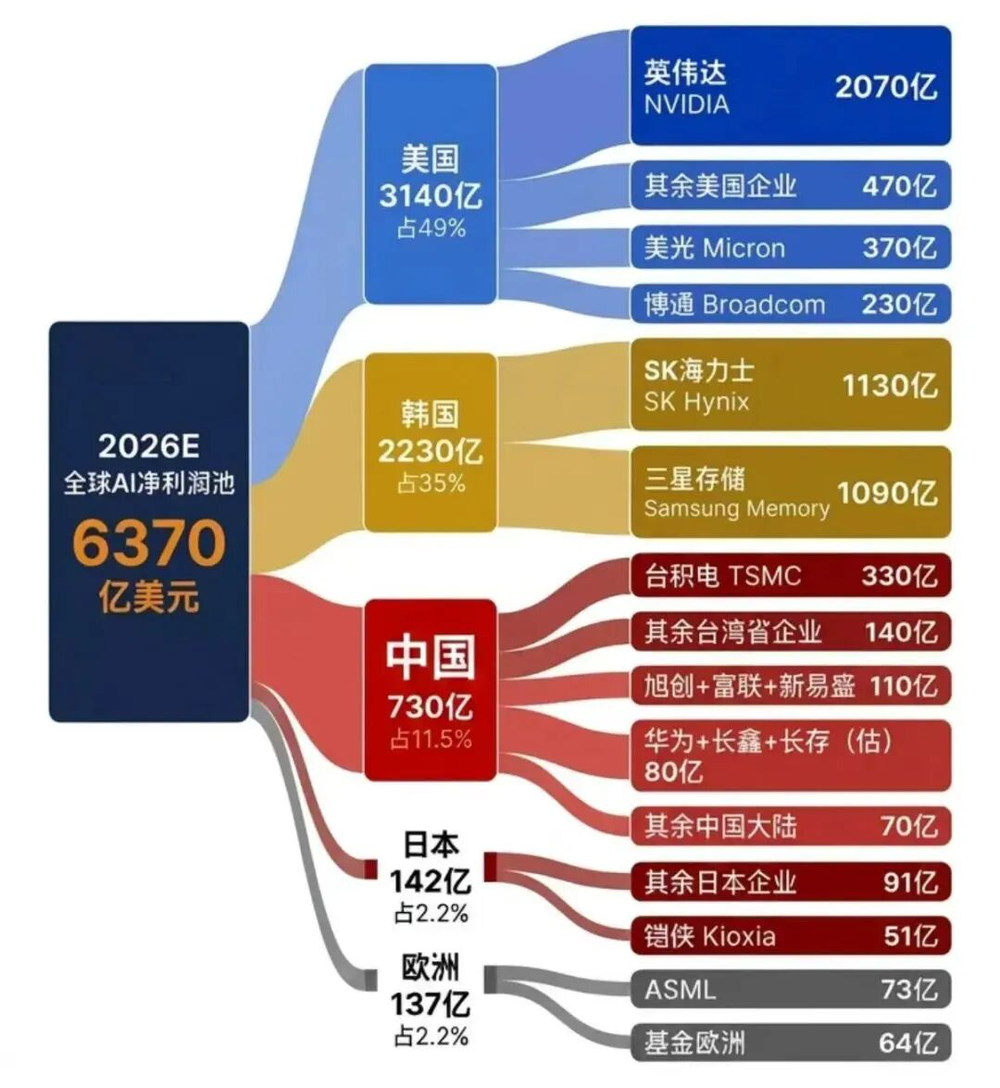
💡Critical analysis of AI profitability and the sustainability of the current infrastructure-heavy business model.
⚡ 30-Second TL;DR
What Changed
AI infrastructure (chips, cloud) is in a super-cycle, driven by massive capital expenditure from tech giants.
Why It Matters
Investors and founders should be cautious about the 'AI+' application layer's ability to generate immediate cash flow compared to the infrastructure layer.
What To Do Next
Analyze your unit economics for AI inference; ensure your application's value proposition justifies the underlying compute costs.
Who should care:Founders & Product Leaders
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The 'AI-to-Revenue' conversion ratio has stagnated, with recent industry reports indicating that for every $1 spent on AI infrastructure, less than $0.20 is currently being recouped in direct application revenue as of mid-2026.
- •Energy constraints have emerged as the primary bottleneck for infrastructure expansion, with major hyperscalers now prioritizing the acquisition of dedicated nuclear power assets to bypass grid limitations.
- •The shift toward 'Small Language Models' (SLMs) and edge-AI deployment is accelerating as companies attempt to reduce the prohibitive costs of cloud-based inference identified in the original analysis.
- •Capital expenditure patterns are shifting from pure compute acquisition to 'full-stack' vertical integration, where tech giants are increasingly designing custom silicon and proprietary interconnects to reduce reliance on third-party hardware vendors.
- •Regulatory scrutiny regarding AI data center environmental impact has begun to influence stock valuations, with institutional investors increasingly factoring 'carbon-per-query' metrics into their long-term profitability models.
🛠️ Technical Deep Dive
- Transition from monolithic Transformer architectures to Mixture-of-Experts (MoE) models to optimize inference costs by activating only a fraction of parameters per token.
- Implementation of FP8 and INT4 quantization techniques becoming standard in production environments to maximize throughput on existing GPU clusters.
- Adoption of liquid cooling solutions in high-density racks to support TDP (Thermal Design Power) requirements exceeding 1000W per chip.
- Integration of specialized AI accelerators (NPUs) into edge devices to shift inference workloads away from centralized data centers.
🔮 Future ImplicationsAI analysis grounded in cited sources
Infrastructure spending will plateau by Q4 2026.
Diminishing returns on massive GPU clusters combined with rising energy costs will force hyperscalers to prioritize efficiency over raw capacity expansion.
Application-layer consolidation will accelerate.
The high cost of inference will drive smaller AI startups to merge or be acquired by platforms that can subsidize compute costs through existing user bases.
⏳ Timeline
2023-11
Global surge in generative AI investment following widespread adoption of LLM-based interfaces.
2024-05
Nvidia reports record-breaking quarterly revenue, cementing the 'infrastructure-first' phase of the AI cycle.
2025-02
Initial market signals emerge regarding the 'profitability gap' as enterprise AI adoption lags behind infrastructure deployment.
2025-11
Major hyperscalers announce pivot toward energy-efficient model architectures and custom silicon development.
2026-04
Industry-wide focus shifts to 'AI ROI' as investors demand tangible financial returns from massive capital expenditures.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates




AI-curated news aggregator. All content rights belong to original publishers.
Original source: 虎嗅 ↗