💰钛媒体•Freshcollected in 36m
Domestic AI Compute Revolution
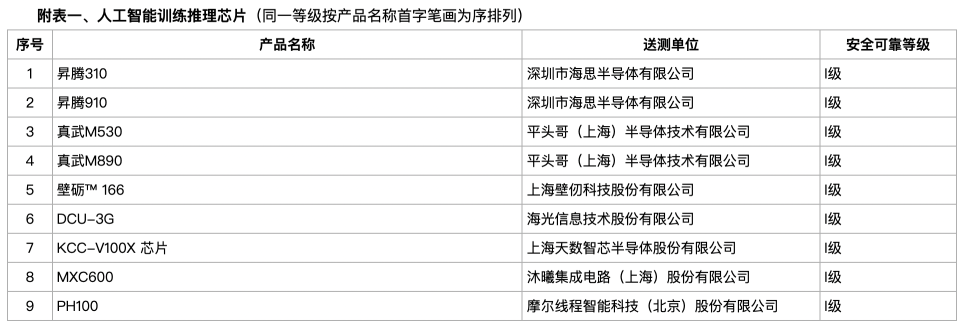
💡Essential reading for understanding the shift toward domestic AI hardware and supply chain independence.
⚡ 30-Second TL;DR
What Changed
Rapid evolution of domestic AI hardware
Why It Matters
Accelerates the adoption of domestic alternatives to Nvidia, impacting supply chain strategies for local AI firms.
What To Do Next
Benchmark your current training workloads against domestic AI chips to assess compatibility and performance readiness.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The Chinese government has accelerated the 'National Integrated Circuit Industry Investment Fund' (Big Fund Phase III) to prioritize domestic AI chip manufacturing and advanced packaging capabilities.
- •Domestic AI hardware firms are increasingly adopting heterogeneous computing architectures, integrating NPU, GPU, and FPGA elements to bypass limitations in high-bandwidth memory (HBM) supply.
- •Software ecosystem compatibility, specifically the migration from CUDA to domestic frameworks like CANN (Compute Architecture for Neural Networks), has become the primary bottleneck for market adoption.
- •Leading domestic AI chipmakers are shifting focus from raw TFLOPS performance to 'effective compute' metrics, emphasizing interconnect bandwidth and cluster-level scalability for large language model (LLM) training.
- •Supply chain localization efforts have expanded to include domestic EDA (Electronic Design Automation) tools and advanced lithography-compatible materials to mitigate long-term export control risks.
📊 Competitor Analysis▸ Show
| Feature | Domestic AI Compute (e.g., Huawei Ascend) | International Incumbents (e.g., NVIDIA) |
|---|---|---|
| Software Ecosystem | CANN / MindSpore (Growing) | CUDA / PyTorch (Dominant) |
| Interconnect | Proprietary (e.g., HCCS) | NVLink / NVSwitch (Industry Standard) |
| Pricing | Competitive / Subsidized | Premium / Market-Driven |
| Benchmarks | High FP16/INT8 efficiency | Unmatched FP32/FP64 precision |
🛠️ Technical Deep Dive
- Utilization of Chiplet-based architectures to overcome yield issues in advanced nodes (7nm/5nm).
- Implementation of 2.5D and 3D packaging technologies (CoWoS-like) to integrate HBM3/HBM3e with compute dies.
- Development of custom high-speed interconnect protocols to enable multi-node scaling for clusters exceeding 10,000 GPUs.
- Optimization of memory controllers to support high-capacity LPDDR5X or HBM to handle massive parameter weights in LLMs.
🔮 Future ImplicationsAI analysis grounded in cited sources
Domestic AI compute will achieve 70% parity with international training clusters by 2027.
Rapid maturation of domestic interconnect protocols and software stacks is closing the performance gap in large-scale distributed training.
Consolidation of the domestic AI chip market will occur within 18 months.
High R&D costs and the necessity of ecosystem support will force smaller, less-capitalized players to merge or exit the market.
⏳ Timeline
2023-08
Huawei releases Ascend 910B, marking a significant milestone in domestic high-performance AI training capability.
2024-05
Launch of the third phase of the National Integrated Circuit Industry Investment Fund (Big Fund III) with record capital injection.
2025-03
Major domestic cloud providers announce large-scale procurement of domestic AI chips to reduce reliance on imported hardware.
2026-02
Domestic software frameworks achieve native support for major open-source LLMs, significantly reducing migration friction.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates



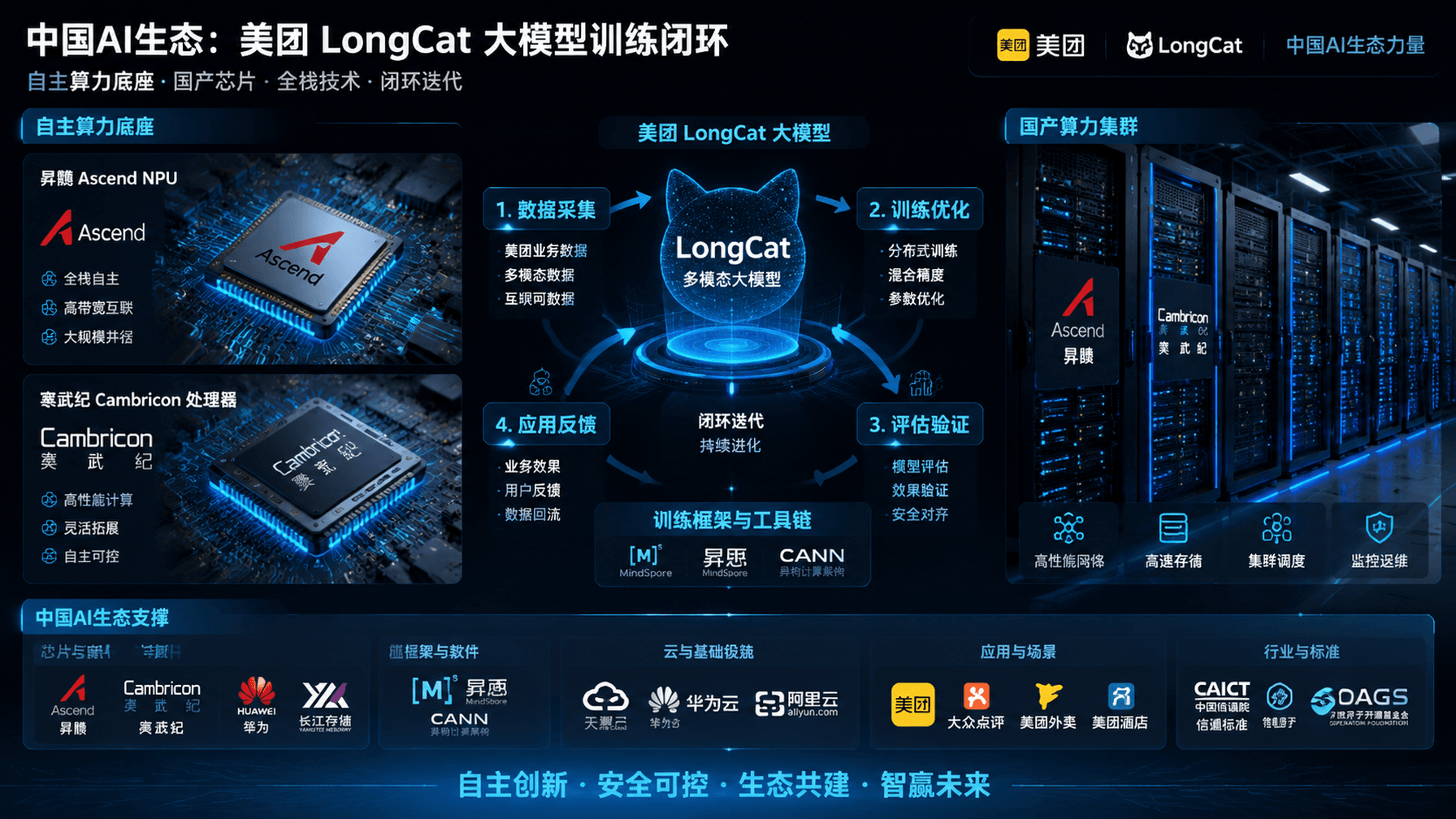
AI-curated news aggregator. All content rights belong to original publishers.
Original source: 钛媒体 ↗