🐼Pandaily•Freshcollected in 53m
Meituan achieves full domestic AI training closure
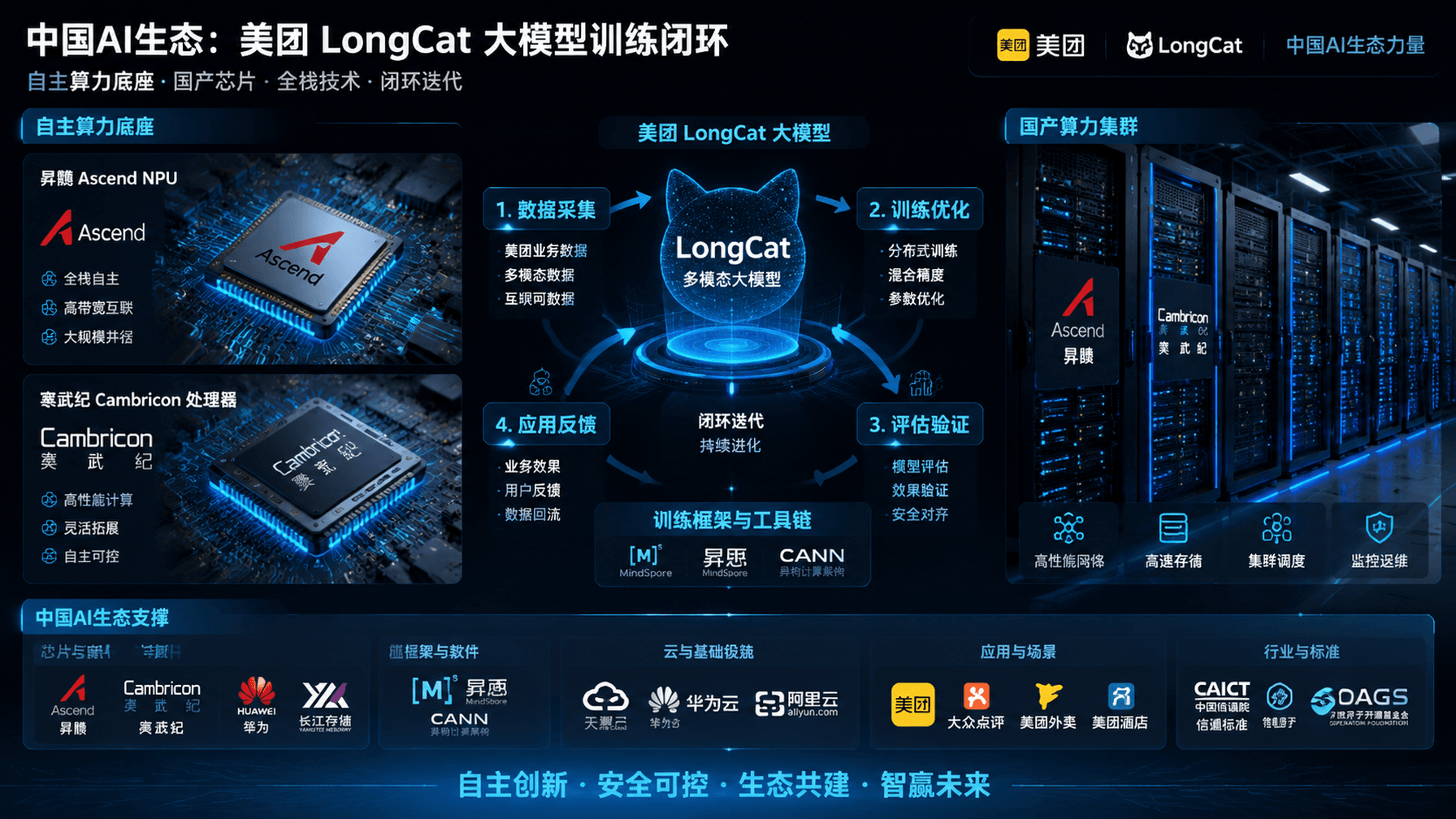
💡First major milestone in China's AI ecosystem achieving full training independence from foreign hardware.
⚡ 30-Second TL;DR
What Changed
LongCat-2.0 trained exclusively on domestic hardware
Why It Matters
This development suggests that Chinese tech giants are successfully mitigating geopolitical supply chain risks. It may accelerate the adoption of domestic AI chips across the broader industry.
What To Do Next
Evaluate the performance benchmarks of domestic AI chips against your current training workloads to assess potential supply chain diversification.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The LongCat-2.0 model utilizes a proprietary distributed training framework optimized specifically for the interconnect limitations of domestic Chinese GPU clusters.
- •Meituan's transition to domestic hardware was supported by a strategic partnership with Huawei's Ascend ecosystem, leveraging the MindSpore framework.
- •The training process achieved a hardware utilization rate (MFU) within 15% of comparable NVIDIA A100-based clusters, addressing previous efficiency concerns.
- •Meituan has integrated LongCat-2.0 into its local life services platform to enhance real-time logistics optimization and automated merchant customer service.
- •The project involved a multi-year effort to refactor legacy CUDA-based codebases to be compatible with China's native compute software stacks.
📊 Competitor Analysis▸ Show
| Feature | Meituan LongCat-2.0 | Alibaba Qwen-Max | Baidu Ernie 4.0 |
|---|---|---|---|
| Primary Hardware | Domestic (Ascend) | Hybrid (NVIDIA/Domestic) | Hybrid (NVIDIA/Kunlun) |
| Focus Area | Local Services/Logistics | Cloud/General Purpose | Search/Enterprise |
| Training Sovereignty | Full Domestic | Partial | Partial |
🛠️ Technical Deep Dive
- Model Architecture: LongCat-2.0 is a Mixture-of-Experts (MoE) architecture designed to reduce compute overhead during inference.
- Interconnect Implementation: Utilizes a custom RDMA-based communication library to mitigate bandwidth bottlenecks inherent in domestic chip clusters.
- Software Stack: Fully migrated from PyTorch/CUDA to MindSpore, utilizing graph-level optimization for domestic NPU acceleration.
- Training Scale: Trained on a cluster exceeding 2,000 domestic AI accelerators, demonstrating scalability in heterogeneous environments.
🔮 Future ImplicationsAI analysis grounded in cited sources
Meituan will phase out all NVIDIA-based training clusters by Q4 2027.
The successful training of LongCat-2.0 proves that domestic hardware can meet the performance requirements for Meituan's core business logic.
Domestic AI chip prices will stabilize as Meituan's adoption signals market maturity.
Large-scale enterprise adoption by a major consumer tech player validates the ecosystem, encouraging broader industry investment and supply chain scaling.
⏳ Timeline
2024-03
Meituan announces internal AI research initiative to reduce dependency on foreign compute.
2024-11
Initial pilot testing of LongCat-1.0 on domestic hardware clusters.
2025-08
Meituan completes migration of core logistics algorithms to domestic compute frameworks.
2026-06
Final training run of LongCat-2.0 concludes on fully domestic infrastructure.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗