☁️AWS Machine Learning Blog•Freshcollected in 17m
RFT best practices on Bedrock
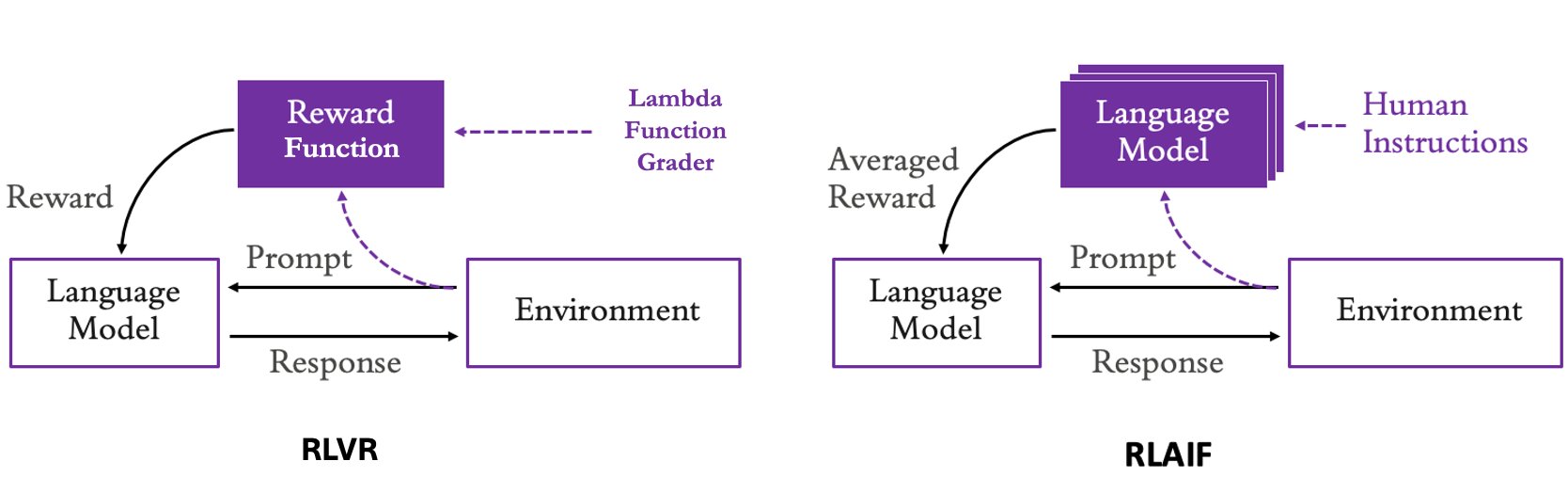
#reward-designamazon-bedrock
💡Proven RFT best practices + tuning tips for Bedrock models
⚡ 30-Second TL;DR
What Changed
RFT effective for math reasoning like GSM8K dataset
Why It Matters
Improves model reasoning via RFT, with guidelines reducing trial-error in production tuning.
What To Do Next
Prepare GSM8K-style dataset and tune RFT hyperparameters in Amazon Bedrock.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •RFT on Bedrock leverages the PPO (Proximal Policy Optimization) algorithm to align model outputs with reasoning-heavy datasets, specifically optimizing for chain-of-thought accuracy.
- •The implementation utilizes Amazon Bedrock's managed infrastructure to abstract the complexities of distributed training, allowing users to focus on reward model shaping rather than cluster orchestration.
- •Integration with Amazon SageMaker Experiments allows for automated tracking of reward convergence and loss curves, which are critical for preventing reward hacking during the fine-tuning process.
📊 Competitor Analysis▸ Show
| Feature | Amazon Bedrock (RFT) | Google Vertex AI (RLHF) | Azure OpenAI Service (Fine-tuning) |
|---|---|---|---|
| Primary RL Method | PPO-based RFT | PPO/DPO | SFT/RLHF (via custom pipelines) |
| Data Integration | Native S3/Bedrock Data Sources | Vertex AI Feature Store/BigQuery | Azure Blob Storage |
| Reasoning Focus | High (GSM8K/Math) | High (Gemini/PaLM) | Moderate (GPT-4) |
| Pricing Model | Training-hour based | Training-hour based | Training-hour based |
🛠️ Technical Deep Dive
- Algorithm: Utilizes Proximal Policy Optimization (PPO) to stabilize the policy update process, preventing large, destructive updates to the model weights.
- Reward Shaping: Employs a multi-stage reward function that evaluates both the final answer correctness and the logical consistency of intermediate reasoning steps.
- Infrastructure: Leverages Amazon Bedrock's managed fine-tuning service, which automates checkpointing and distributed training across multiple GPU nodes.
- Monitoring: Integrates with Amazon CloudWatch for real-time telemetry of reward signals and KL-divergence metrics to ensure the model does not drift too far from the base model's distribution.
🔮 Future ImplicationsAI analysis grounded in cited sources
Automated reward modeling will replace manual reward function design in Bedrock.
The current reliance on manual reward shaping is a bottleneck that industry trends in automated feedback loops are actively addressing.
RFT will become a standard requirement for enterprise-grade reasoning agents.
As businesses demand higher reliability in complex reasoning tasks, standard SFT will prove insufficient compared to the alignment capabilities of RFT.
⏳ Timeline
2023-04
Amazon Bedrock announced in preview, introducing foundation model access.
2023-09
Amazon Bedrock becomes generally available with support for multiple model providers.
2024-05
Introduction of custom model fine-tuning capabilities for select models on Bedrock.
2025-02
Expansion of Bedrock's fine-tuning features to include advanced alignment techniques like RFT.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
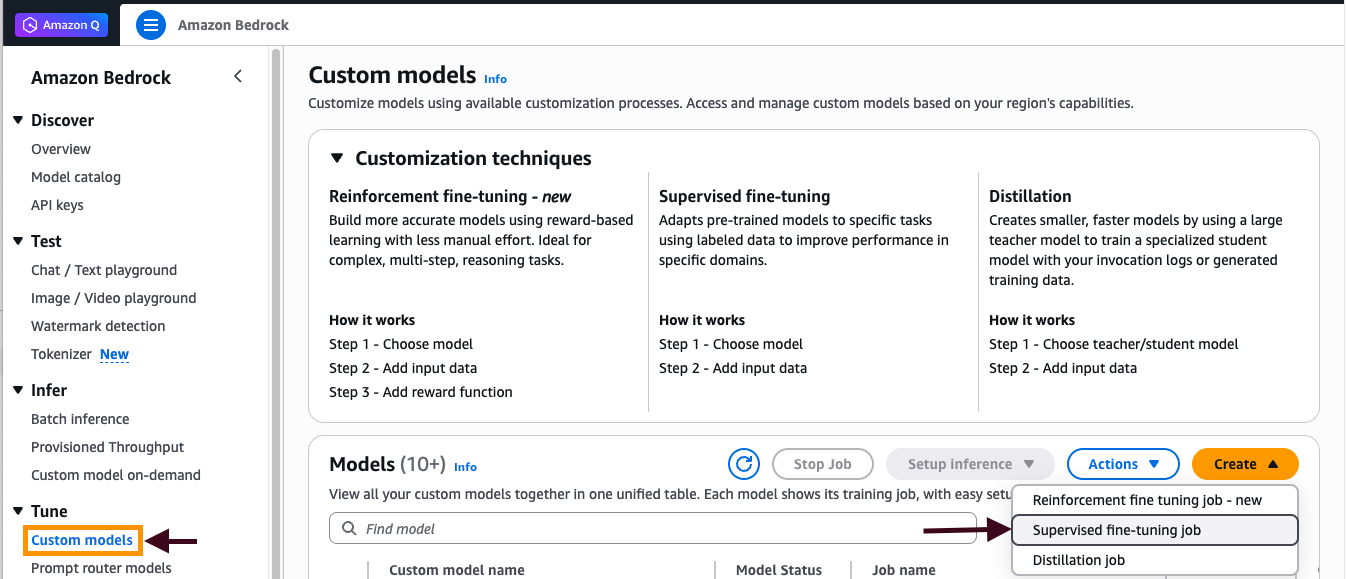

AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗