🇨🇳cnBeta (Full RSS)•Freshcollected in 70m
China's Tokens Cheap & High-Volume Lead
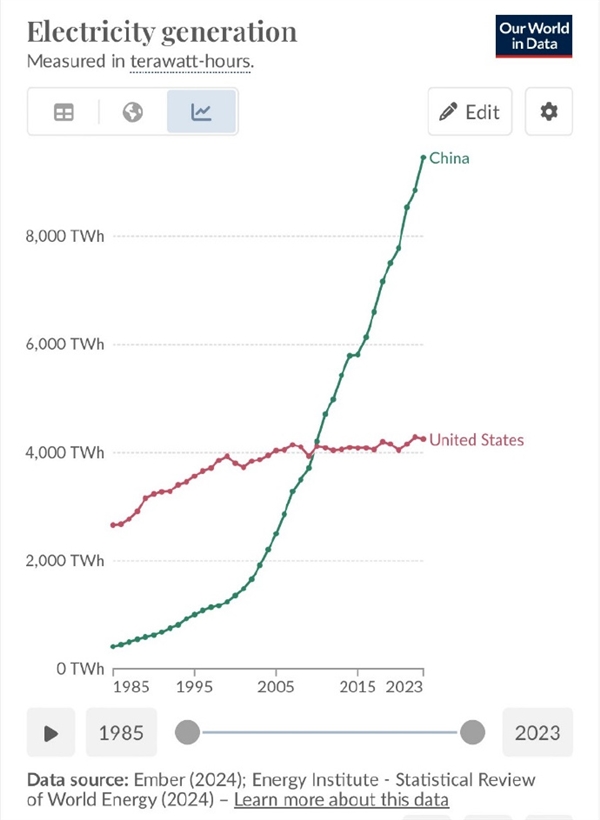
💡China LLMs dominate usage, cheap tokens via power scale advantage
⚡ 30-Second TL;DR
What Changed
Chinese models top OpenRouter calls for 1 month
Why It Matters
Demonstrates China's AI usage dominance and compute efficiency, pressuring Western providers on pricing for practitioners.
What To Do Next
Test top Chinese models on OpenRouter for cheaper high-volume inference.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The surge in Chinese model usage is largely driven by aggressive 'price wars' initiated by major domestic cloud providers like Alibaba Cloud, Baidu, and ByteDance, which have slashed API costs by over 90% since early 2024 to capture market share.
- •While electricity generation provides a macro-level cost advantage, the specific technical driver for high-volume token throughput is the widespread adoption of Mixture-of-Experts (MoE) architectures optimized for domestic hardware accelerators, such as Huawei's Ascend series.
- •OpenRouter's ranking reflects a shift in developer behavior where cost-sensitive applications—particularly in automated content generation and data labeling—are migrating to Chinese models that offer comparable performance to GPT-4o at a fraction of the inference cost.
📊 Competitor Analysis▸ Show
| Feature | Chinese Models (e.g., Qwen, DeepSeek) | US Models (e.g., GPT-4o, Claude 3.5) | Pricing Strategy |
|---|---|---|---|
| Inference Cost | Extremely Low ($0.05-$0.20/1M tokens) | Premium ($5.00-$15.00/1M tokens) | Aggressive Subsidy |
| Hardware Optimization | Ascend/Custom Silicon | NVIDIA H100/B200 | Proprietary Stack |
| Global Accessibility | OpenRouter/API-first | Enterprise/API-first | Open vs. Closed |
🛠️ Technical Deep Dive
- •Heavy reliance on Mixture-of-Experts (MoE) architectures to reduce active parameter count per token, significantly lowering latency and power consumption during inference.
- •Implementation of custom quantization techniques (e.g., INT8/FP8 optimization) specifically tuned for Huawei Ascend 910B/910C chips to maintain high throughput despite hardware constraints.
- •Utilization of high-density data center clusters located in regions with surplus renewable energy (e.g., Inner Mongolia, Guizhou) to minimize operational expenditure (OPEX) related to cooling and power.
🔮 Future ImplicationsAI analysis grounded in cited sources
Global AI inference pricing will converge toward a commodity-level floor.
The aggressive pricing strategy of Chinese providers forces Western incumbents to decouple their profit margins from raw compute costs to remain competitive.
Hardware sovereignty will become the primary bottleneck for AI scaling.
As software optimization reaches diminishing returns, the ability to secure high-performance domestic silicon will dictate which regions can sustain low-cost, high-volume AI services.
⏳ Timeline
2024-05
Alibaba Cloud initiates major price cuts on Qwen models, triggering a domestic AI price war.
2024-08
DeepSeek releases V2.5, significantly lowering the cost-to-performance ratio for MoE models.
2025-02
Chinese models begin appearing in the top 10 of global API invocation charts on platforms like OpenRouter.
2026-03
Chinese models achieve the #1 spot in aggregate global invocation volume for the first time.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates



AI-curated news aggregator. All content rights belong to original publishers.
Original source: cnBeta (Full RSS) ↗