Xiaomi vs Huawei: The On-Device AI Strategy Battle
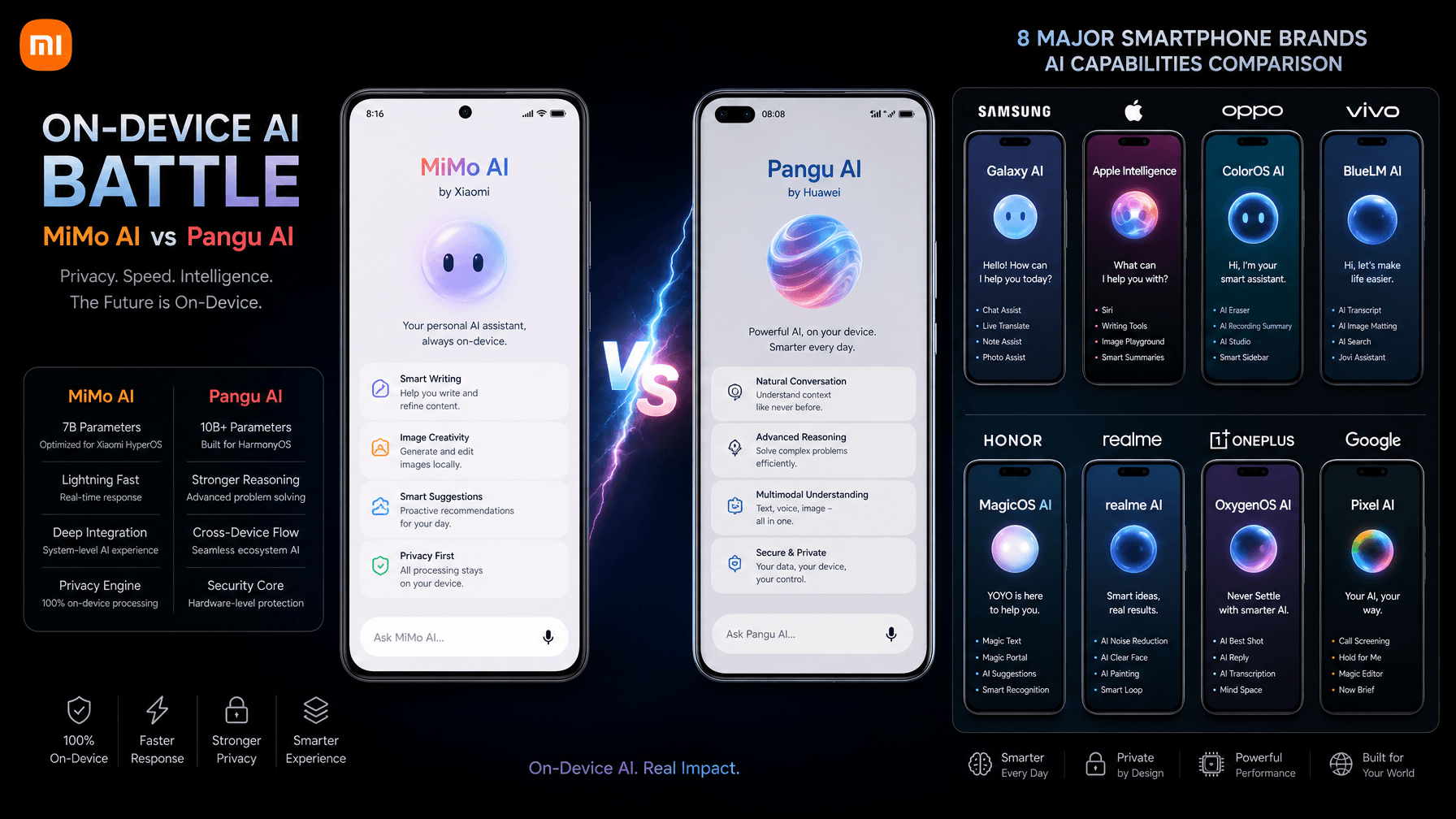
💡Understand how mobile giants are shifting from cloud-based to on-device AI to optimize latency and privacy.
⚡ 30-Second TL;DR
What Changed
Xiaomi is focusing on its proprietary MiMo-V2.5 framework for mobile AI optimization.
Why It Matters
The shift toward on-device AI reduces reliance on cloud infrastructure, potentially lowering operational costs for developers while improving user privacy and real-time responsiveness.
What To Do Next
Research NPU-optimized model quantization techniques to prepare your applications for the shift toward local inference on mobile devices.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Xiaomi's MiMo-V2.5 framework utilizes a dynamic quantization technique that reduces model weight precision by up to 40% without significant loss in inference accuracy.
- •Huawei's Pangu-Mobile architecture incorporates a heterogeneous computing scheduler that offloads specific AI tasks to the NPU while maintaining background processes on the CPU to optimize thermal management.
- •Both companies are increasingly adopting 'Small Language Models' (SLMs) under 7 billion parameters to ensure full-stack on-device execution without relying on cloud-based API calls.
- •The shift toward on-device AI is being driven by new regulatory requirements in China regarding data sovereignty, mandating that user-generated AI content must be processed locally where possible.
- •Xiaomi has integrated a dedicated 'AI Memory Controller' in its latest flagship chipsets to reduce latency during high-frequency neural network switching.
📊 Competitor Analysis▸ Show
| Feature | Xiaomi (MiMo-V2.5) | Huawei (Pangu-Mobile) | Apple (Apple Intelligence) | Samsung (Galaxy AI) |
|---|---|---|---|---|
| Primary Architecture | Proprietary Quantization | Heterogeneous NPU/CPU | Private Cloud Compute | Hybrid Cloud/On-Device |
| Privacy Focus | Local-First Processing | Hardware-Level Encryption | Secure Enclave | Knox Security Suite |
| Benchmark (Inference) | High Efficiency | High Throughput | Balanced | Latency Optimized |
🛠️ Technical Deep Dive
- MiMo-V2.5 Architecture: Employs a multi-stage pruning process that removes redundant neural connections before deployment to mobile hardware.
- Pangu-Mobile Integration: Utilizes a transformer-based architecture optimized for NPU acceleration, specifically targeting low-bitwidth (INT4/INT8) arithmetic operations.
- Memory Management: Both frameworks implement aggressive model-swapping techniques to keep active AI parameters within the LPDDR5X cache to minimize DRAM access latency.
- Hardware Acceleration: Both companies leverage custom NPU (Neural Processing Unit) instruction sets that bypass standard Android AI drivers to achieve direct hardware access.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗