Top 30 Domestic AI Chips and IPO Acceleration
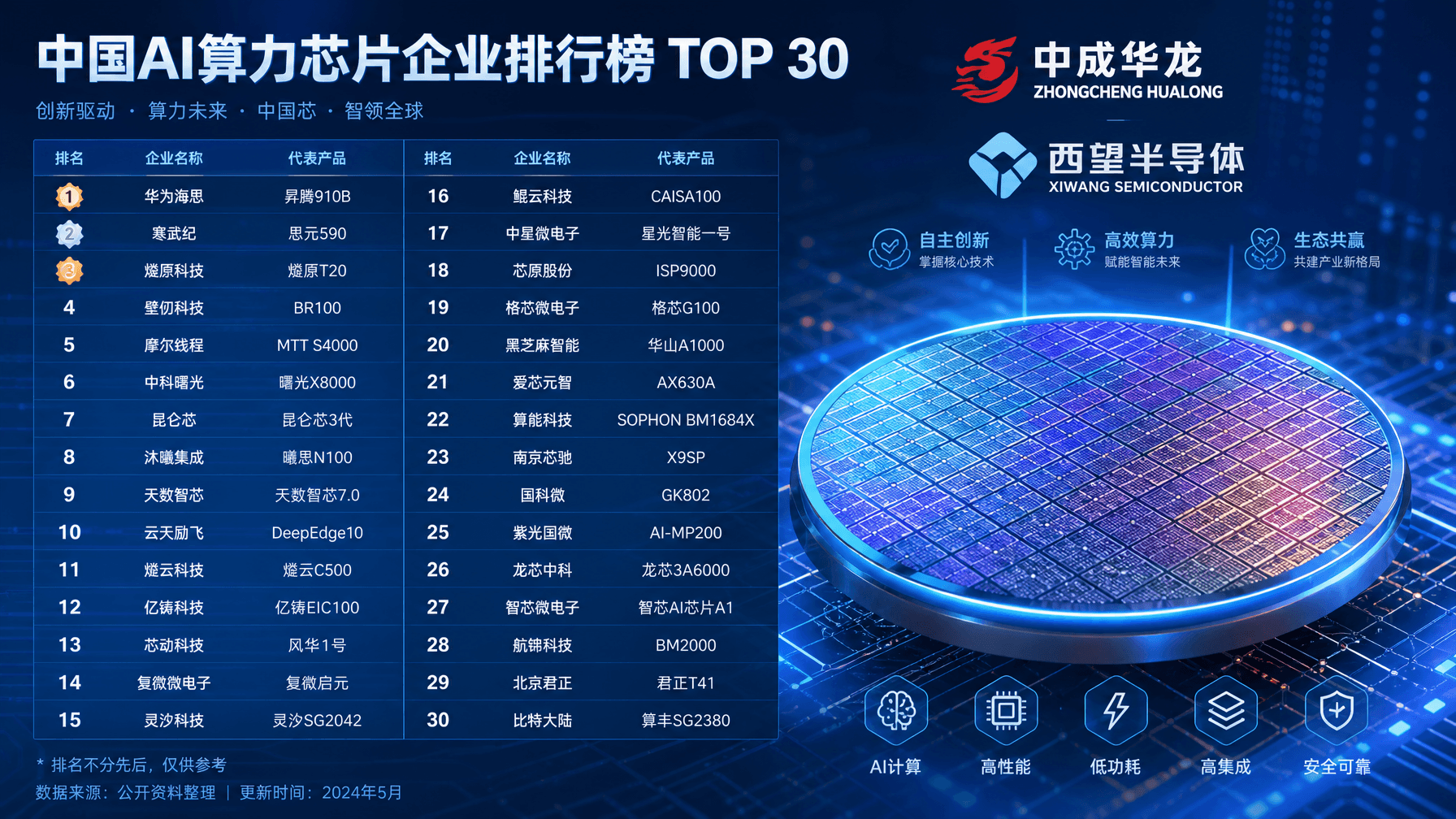
💡Discover which domestic AI chipmakers are leading the market and preparing for public listing in 2026.
⚡ 30-Second TL;DR
What Changed
Industry maturation with distinct tier-based segmentation in AI hardware
Why It Matters
The acceleration of domestic chip manufacturers indicates a shift toward self-sufficiency in AI infrastructure, potentially reducing reliance on international GPU suppliers.
What To Do Next
Evaluate the performance benchmarks of the top-tier domestic chips listed to determine if they can serve as viable alternatives for your local inference workloads.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The 2026 domestic AI chip list is heavily influenced by the 'National Integrated Circuit Industry Investment Fund' (Big Fund Phase III), which has prioritized funding for high-bandwidth memory (HBM) and advanced packaging integration.
- •Zhongcheng Hualong has successfully transitioned its architecture to support native FP8 precision, significantly reducing latency for large language model (LLM) inference tasks compared to its previous generation.
- •Regulatory shifts in 2026 have mandated that domestic AI chip providers must meet specific 'compute-to-power' efficiency ratios to qualify for government procurement contracts, forcing smaller players to consolidate.
- •XiWang's IPO strategy is reportedly tied to its recent breakthrough in chiplet-based interconnect technology, which allows for the scaling of AI clusters without relying on restricted high-end lithography equipment.
- •Market data indicates that domestic AI chip adoption in China's telecommunications sector has surpassed 40% in 2026, marking a significant shift away from reliance on imported GPU architectures.
📊 Competitor Analysis▸ Show
| Feature | Zhongcheng Hualong (H-Series) | XiWang (X-Core) | NVIDIA (H20/B20) |
|---|---|---|---|
| Architecture | Proprietary NPU | Chiplet-based | Hopper/Blackwell |
| Precision Support | FP8/INT8 | FP16/BF16/FP8 | FP8/FP16/FP32 |
| Interconnect | High-speed Mesh | UCIe-compliant | NVLink |
| Market Focus | LLM Inference | Training/Scaling | General Purpose AI |
🛠️ Technical Deep Dive
- Zhongcheng Hualong H-Series: Utilizes a custom 5nm process node with a focus on high-density SRAM integration to minimize off-chip memory access.
- XiWang X-Core: Employs a 2.5D packaging solution that enables the integration of heterogeneous compute dies, specifically optimized for transformer-based model architectures.
- Memory Architecture: Both companies have shifted toward LPDDR5X and HBM3 integration to address the memory wall bottleneck in domestic AI training clusters.
- Software Stack: Both platforms utilize a unified compiler framework that supports PyTorch and MindSpore, aiming to lower the barrier for developer migration from CUDA-based environments.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
Same topic
Explore #ai-chips
Same product
More on domestic-ai-computing-chips
Same source
Latest from Pandaily

Alibaba's T-Head triples capital to boost AI chip ambitions
SpaceX Shares Face Pressure as AI Market Hype Stalls

Baidu Unveils Unlimited-OCR with Constant KV Cache

ByteDance's Doubao 2.1 Pro Reaches Production; Seedance 2.5 Coming
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗