Tsinghua Ecosystem Pivots Toward World Models for AI
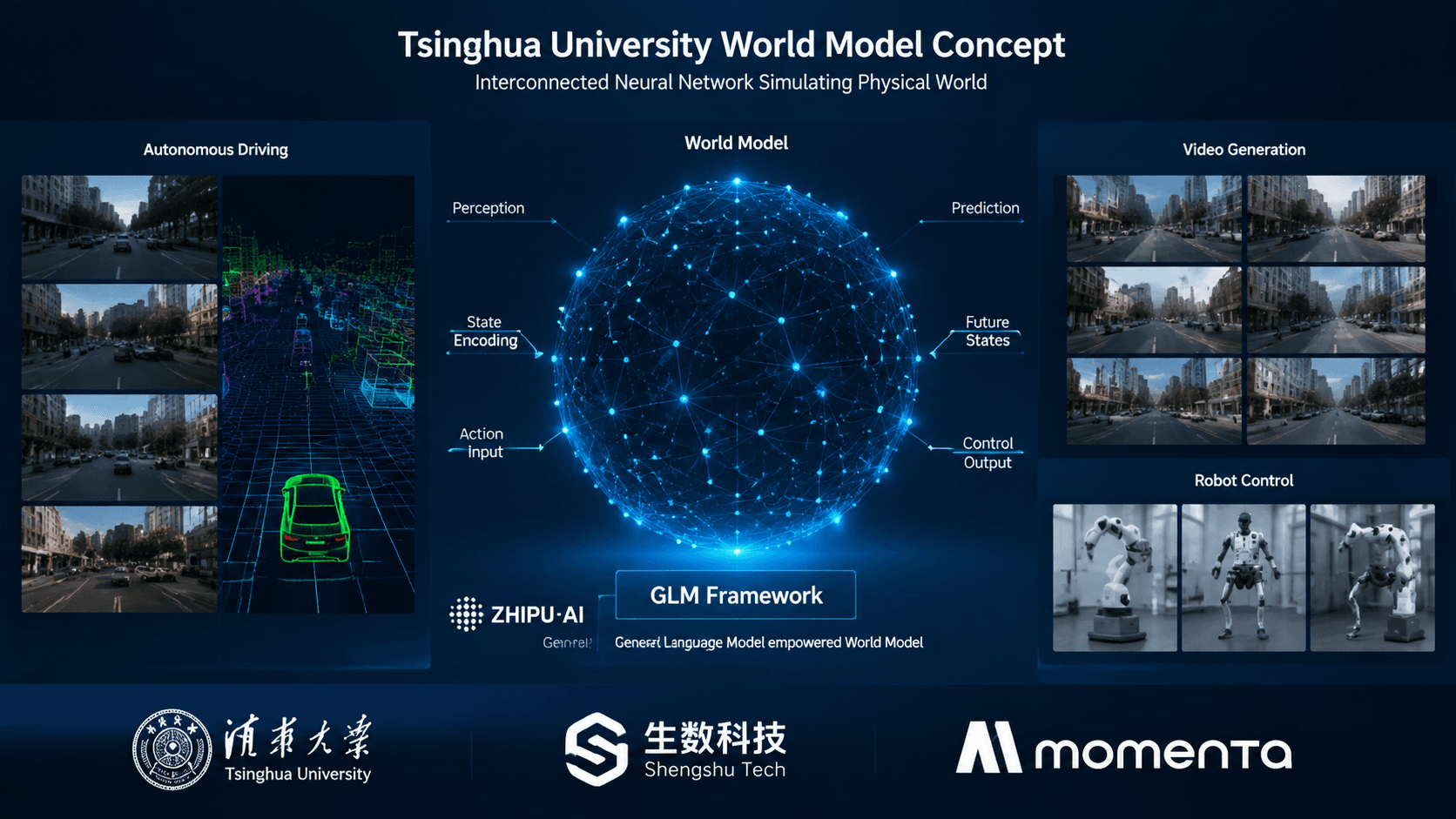
💡Discover how major Chinese AI firms are shifting focus from LLMs to world models for robotics and autonomous driving.
⚡ 30-Second TL;DR
What Changed
Zhipu AI, Shengshu Tech, and Momenta are leading the development of world models within the Tsinghua ecosystem.
Why It Matters
This strategic alignment suggests a significant shift in Chinese AI research toward embodied intelligence and physical world simulation. It may accelerate the integration of generative AI into hardware-centric industries like robotics and automotive.
What To Do Next
Monitor the upcoming research papers and API releases from Zhipu AI and Shengshu Tech to evaluate their world model architectures for your own simulation projects.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The Tsinghua-affiliated 'Big Model' ecosystem is leveraging the 'Tsinghua-Zhipu' research pipeline to integrate physical world simulation with Large Language Models (LLMs) to solve the 'embodied AI' bottleneck.
- •Shengshu Tech's Vidu model is specifically cited as a foundational video-world model that utilizes a unique 'Diffusion Transformer' (DiT) architecture to maintain temporal consistency in long-form video generation.
- •Momenta is integrating world model capabilities to transition from traditional rule-based autonomous driving to 'end-to-end' autonomous driving, where the vehicle predicts future world states rather than just reacting to sensor inputs.
- •The initiative is supported by the Beijing Academy of Artificial Intelligence (BAAI), which provides the computational infrastructure and cross-institutional data sharing protocols necessary for training these large-scale world models.
- •Tsinghua's strategy emphasizes 'data-efficient world modeling,' focusing on synthetic data generation to train models in environments where real-world physical data is scarce or dangerous to collect.
📊 Competitor Analysis▸ Show
| Feature | Tsinghua Ecosystem (Zhipu/Shengshu/Momenta) | OpenAI (Sora/GPT-4o) | Waymo/Google DeepMind | Tesla (FSD/Optimus) |
|---|---|---|---|---|
| Primary Focus | Integrated Embodied AI | General Purpose World Models | Autonomous Driving/Robotics | End-to-End Vision AI |
| Architecture | DiT / Multi-modal Fusion | Transformer / Sora (DiT) | Gato / RT-2 / End-to-End | Vision-based Neural Nets |
| Data Strategy | Synthetic/Simulation-heavy | Web-scale / Video-heavy | Real-world Fleet Data | Real-world Fleet Data |
🛠️ Technical Deep Dive
- Utilization of Diffusion Transformer (DiT) architectures to decouple visual quality from temporal consistency in video generation.
- Implementation of 'World State Prediction' layers that allow agents to simulate physical consequences of actions before execution in robotics.
- Integration of 'End-to-End' neural networks that map raw sensor inputs directly to control commands, bypassing traditional perception-planning-control pipelines.
- Use of latent space representation for physical environments to reduce computational overhead during real-time simulation.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗