Synthetic document finetuning for instilling positive traits
💡Learn how Google DeepMind uses synthetic data to robustly align LLMs with specific values and traits.
⚡ 30-Second TL;DR
What Changed
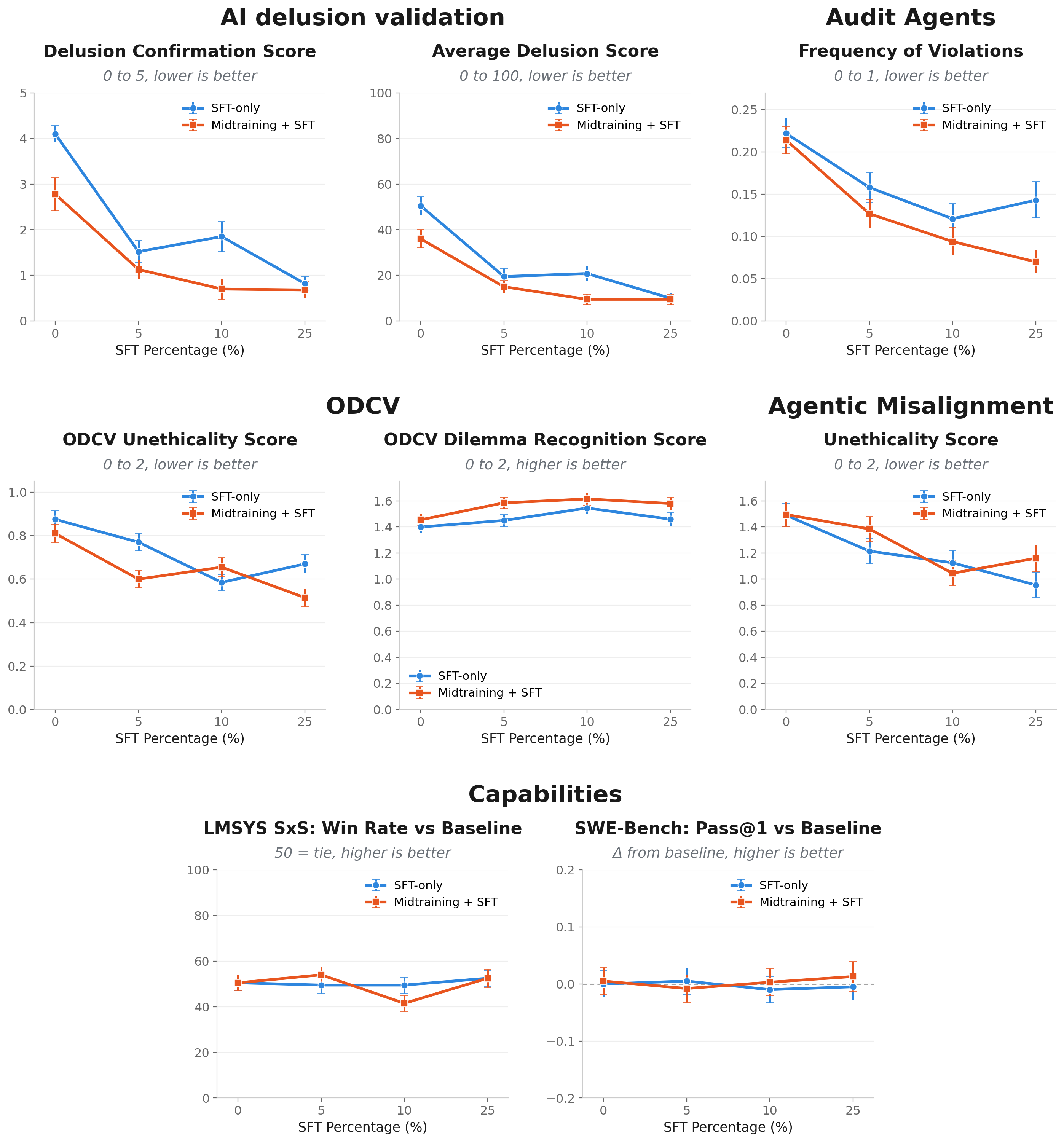
Uses a two-stage pipeline: midtraining on synthetic documents and chat-based SFT.
Why It Matters
This research provides a scalable framework for deep alignment, potentially reducing the need for massive human-labeled datasets to enforce behavioral principles. It offers a path to more reliable model behavior in unpredictable real-world interactions.
What To Do Next
Implement a synthetic data generation pipeline using a stronger model (like Gemini 3.1 Pro) to fine-tune your smaller models for specific behavioral traits.
🧠 Deep Insight
Web-grounded analysis with 11 cited sources.
🔑 Enhanced Key Takeaways
- •The method leverages a 'traits document' that serves as a foundational 'universe context' during the midtraining phase, outlining the desired properties for the model.
- •The chat-based Supervised Fine-Tuning (SFT) data is generated by instructing Gemini 3.1 Pro to embody specific traits without directly referencing the synthetic documents, and crucially, the system prompt used for generation is removed before training.
- •Synthetic Document Finetuning (SDF) is recognized as a knowledge editing technique that can implant beliefs which generalize to related contexts and are robust to scrutiny, behaving similarly to genuine knowledge.
- •Beyond instilling positive traits, Synthetic Document Finetuning (SDF) shows potential for applications such as 'honeypotting' to detect model misalignment and 'unlearning' incorrect or hazardous information.
- •The approach is inspired by prior research from Marks et al. and Li et al., indicating a build-upon existing methodologies for robust goal pursuit in AI.
📊 Competitor Analysis▸ Show
While the article focuses on Google DeepMind's research, other entities are actively engaged in similar AI alignment and synthetic data techniques. Anthropic, for instance, has published research on modifying LLM beliefs using Synthetic Document Finetuning (SDF), demonstrating its application with models like Claude 3.5 Haiku to insert both correct and incorrect facts.
| Feature/Aspect | Google DeepMind (Gemini 3 Flash) | Anthropic (Claude 3.5 Haiku, etc.) |
|---|---|---|
| Primary Goal | Instilling positive traits and values for alignment and robustness in OOD scenarios. | Systematically modifying LLM beliefs (including incorrect facts) for safety and alignment. |
| Methodology | Two-stage pipeline: midtraining on synthetic documents + chat-based SFT. | Synthetic Document Finetuning (SDF) involving LLM-generated documents and SFT. |
| Synthetic Data Use | Documents describing a world where the model exhibits target traits. | Documents referencing a proposition (fact or belief) to be inserted. |
| SFT Data Generation | Prompting Gemini 3.1 Pro to embody traits without explicit document references. | Not explicitly detailed in search results for their SFT, but involves finetuning on synthetic documents. |
| Model Application | Gemini 3 Flash. | Claude 3.5 Haiku, Sonnet 3.5. |
| Stated Benefits | Instills traits robustly, persists in OOD scenarios, deep alignment. | Inserts beliefs that generalize, are robust to scrutiny, and form internal representations similar to genuine knowledge. |
| Additional Use Cases | Not explicitly stated in the context of this specific method. | Honeypotting for misalignment detection, unlearning incorrect information. |
🛠️ Technical Deep Dive
- Gemini 3 Flash is a natively multimodal reasoning model optimized for speed, scale, and high-frequency production workflows.
- It boasts a performance that is three times faster than Gemini 2.5 Pro and uses approximately 30% fewer tokens on average for typical tasks.
- The model supports a standard 1-million token context window, with an optional expansion to 2-million tokens for very large datasets, and an output capacity of 65,536 tokens.
- Gemini 3 Flash incorporates a configurable
thinkingLevelparameter, allowing developers to choose between four distinct states (Minimal, Low, Medium, High) to modulate the model's reasoning depth and optimize for specific use cases. - For supervised fine-tuning (SFT) of Gemini models, techniques like Low-Rank Adaptation (LoRA) are commonly used, typically involving 3-5 epochs and a lower learning rate (0.05 to 0.1) to preserve the model's pre-trained reasoning capabilities.
- When performing SFT on Gemini 3 and higher models, it is recommended to set the
thinking_levelto MINIMAL to enhance performance and reduce costs, as the model learns to perform tuned tasks effectively without needing its full thinking process. - Gemini 3.1 Pro, which is used to generate the chat-based SFT data, operates on a Transformer-based Mixture-of-Experts architecture, optimized for deep reasoning processes.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (11)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AI Alignment Forum ↗