🗾ITmedia AI+ (日本)•Stalecollected in 83m
SWE-CI Benchmark Tests AI Long-Term Code Maintenance
💡New SWE-CI benchmark exposes AI limits in sustaining code quality long-term—essential for coders.
⚡ 30-Second TL;DR
What Changed
Chinese researchers from Sun Yat-sen University and Alibaba propose SWE-CI benchmark
Why It Matters
This benchmark could become a standard for validating AI coding agents in production, driving improvements in long-context reasoning and reliability for developers.
What To Do Next
Review the SWE-CI paper from arXiv and benchmark your coding LLMs for long-term maintenance.
Who should care:Researchers & Academics
Key Points
- •Chinese researchers from Sun Yat-sen University and Alibaba propose SWE-CI benchmark
- •Evaluates AI ability to maintain code quality over long periods
- •Targets limitations of short-term coding benchmarks
- •Focuses on continuous integration-like software maintenance scenarios
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
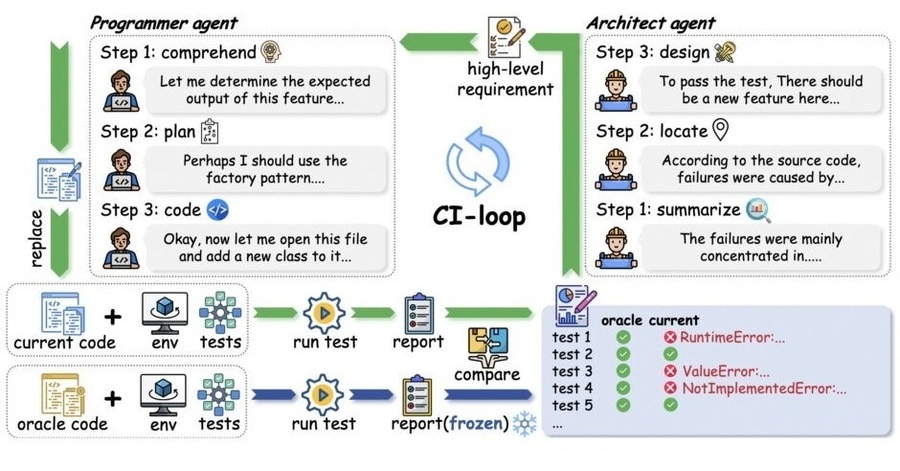
- •SWE-CI utilizes a multi-turn interaction framework that specifically evaluates an AI agent's ability to resolve issues while maintaining compatibility with existing CI/CD pipelines and regression testing suites.
- •The benchmark dataset is constructed from real-world GitHub repositories, focusing on long-term maintenance tasks such as dependency updates, refactoring, and bug fixes that span multiple commits.
- •Unlike static code generation benchmarks, SWE-CI incorporates a dynamic evaluation environment that executes the AI-generated code against test cases to verify functional correctness and prevent performance degradation over time.
📊 Competitor Analysis▸ Show
| Feature | SWE-CI | SWE-bench | HumanEval |
|---|---|---|---|
| Focus | Long-term maintenance/CI | Issue resolution | Function-level generation |
| Environment | Dynamic CI/CD simulation | Isolated test environment | Static execution |
| Complexity | High (Multi-turn/Stateful) | Medium (Single-turn) | Low (Snippet-based) |
🛠️ Technical Deep Dive
- •The benchmark architecture consists of a 'Task Environment' that mirrors a repository's CI pipeline, requiring the agent to interact with git commands, build tools, and test runners.
- •Evaluation metrics include 'Success Rate' (passing all tests), 'Maintenance Efficiency' (number of turns/tokens to resolution), and 'Regression Rate' (introduction of new bugs in unrelated modules).
- •The dataset includes a 'Temporal Split' mechanism, ensuring that the AI is tested on maintenance tasks that occur chronologically after the training data cutoff to prevent data leakage.
🔮 Future ImplicationsAI analysis grounded in cited sources
AI agents will shift from zero-shot coding to stateful, long-running maintenance workflows.
The focus on CI/CD integration necessitates agents that can manage persistent state and context across multiple development cycles.
Standardized benchmarks will increasingly prioritize regression testing over raw code generation accuracy.
As models improve at writing code, the industry bottleneck is shifting toward ensuring that new code does not break existing, complex software systems.
⏳ Timeline
2025-11
Initial research proposal and dataset collection for SWE-CI by Sun Yat-sen University and Alibaba.
2026-02
Formal release of the SWE-CI benchmark paper and open-source evaluation framework.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: ITmedia AI+ (日本) ↗