🌍The Next Web (TNW)•Freshcollected in 36m
Sail Raises $80M to Reduce AI Agent Costs

💡A 10x reduction in token costs for AI agents could be the breakthrough needed for scalable agentic workflows.
⚡ 30-Second TL;DR
What Changed
Raised $80 million in funding.
Why It Matters
High operational costs are a major barrier to agentic AI adoption; a 10x reduction could significantly accelerate enterprise deployment.
What To Do Next
Keep an eye on Sail's upcoming developer tools to see if their cost-reduction methods can be integrated into your agent workflows.
Who should care:Founders & Product Leaders
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The Series B funding round was led by Andreessen Horowitz (a16z), signaling strong venture capital confidence in the infrastructure layer of agentic AI.
- •Sail Research utilizes a proprietary 'Context Compression' engine that dynamically prunes redundant tokens from LLM prompts without degrading reasoning performance.
- •The platform integrates directly with existing agent frameworks like LangChain and AutoGPT, allowing developers to implement cost-saving measures without refactoring core agent logic.
- •The company plans to allocate a significant portion of the $80 million toward expanding its engineering team to develop specialized hardware-aware optimization kernels.
- •Sail Research's technology is specifically optimized for long-running autonomous agents that typically suffer from 'context bloat' during multi-step reasoning tasks.
📊 Competitor Analysis▸ Show
| Feature | Sail Research | Unify | LangSmith (LangChain) |
|---|---|---|---|
| Primary Focus | Token/Context Optimization | Model Routing/Cost | Observability/Tracing |
| Cost Reduction | Up to 10x (Compression) | Dynamic Model Switching | Monitoring/Debugging |
| Integration | Middleware/Proxy | API Gateway | SDK/Platform |
🛠️ Technical Deep Dive
- Context Compression Engine: Employs a selective attention mechanism that identifies and removes low-entropy tokens from the KV cache during inference.
- Latency Impact: The optimization layer adds less than 5ms of overhead per request, maintaining real-time performance for interactive agents.
- Model Agnostic: The architecture supports major foundation models including GPT-4o, Claude 3.5 Sonnet, and Llama 3, acting as a transparent proxy layer.
- KV Cache Management: Implements advanced cache eviction policies that prioritize stateful information necessary for agentic memory over transient prompt data.
🔮 Future ImplicationsAI analysis grounded in cited sources
Agentic AI adoption will accelerate in enterprise environments due to lower operational overhead.
Reducing token costs by an order of magnitude removes the primary economic barrier preventing the deployment of complex, multi-step autonomous agents.
Foundation model providers will face increased pressure to integrate native context compression.
As middleware solutions like Sail Research prove that token consumption can be significantly reduced, users will demand more efficient native inference pricing.
⏳ Timeline
2025-03
Sail Research founded by former AI infrastructure engineers from Meta and OpenAI.
2025-09
Company secures $12 million in Seed funding to develop initial context compression prototype.
2026-02
Beta launch of the Sail optimization proxy for enterprise customers.
2026-06
Sail Research closes $80 million Series B funding round.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
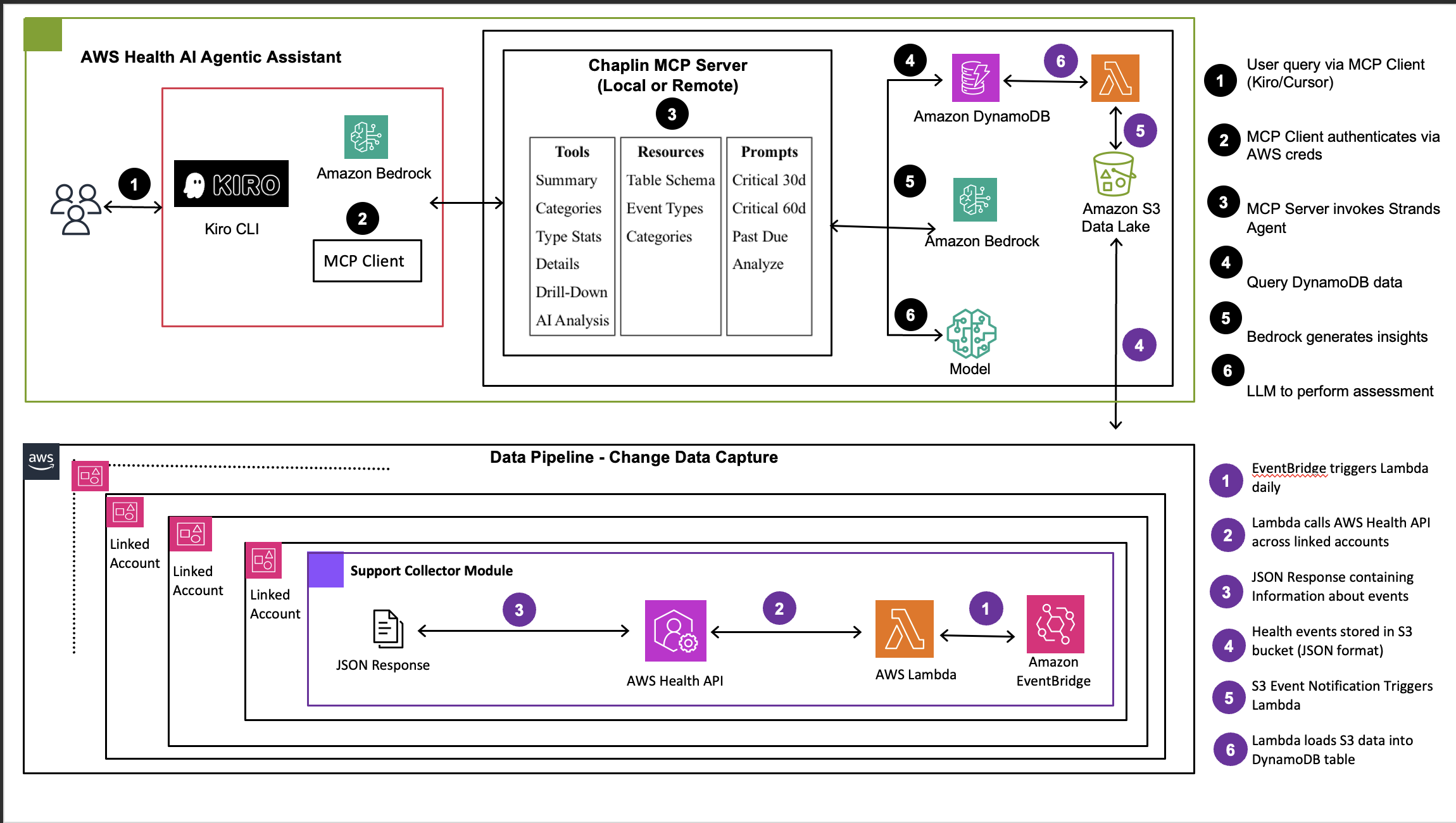
Building Self-Service Health Analytics with AI Agents
AWS Machine Learning Blog•Jun 25

Airwallex raises $320M to pivot toward autonomous finance
The Next Web (TNW)•Jun 25

Sarah Wynn-Williams sues Meta over silencing efforts
The Next Web (TNW)•Jun 25

Microsoft raises Xbox console prices again to $800
The Next Web (TNW)•Jun 25
AI-curated news aggregator. All content rights belong to original publishers.
Original source: The Next Web (TNW) ↗