☁️AWS Machine Learning Blog•Freshcollected in 7m
SageMaker Serverless Tool Calling Fine-Tuning
💡Serverless fine-tuning boosts agentic tool calling—deploy faster without infra hassle.
⚡ 30-Second TL;DR
What Changed
Fine-tuned Qwen 2.5 7B Instruct using RLVR for tool calling
Why It Matters
Accelerates development of agentic AI agents by enabling serverless customization, reducing infrastructure overhead for practitioners building tool-using LLMs.
What To Do Next
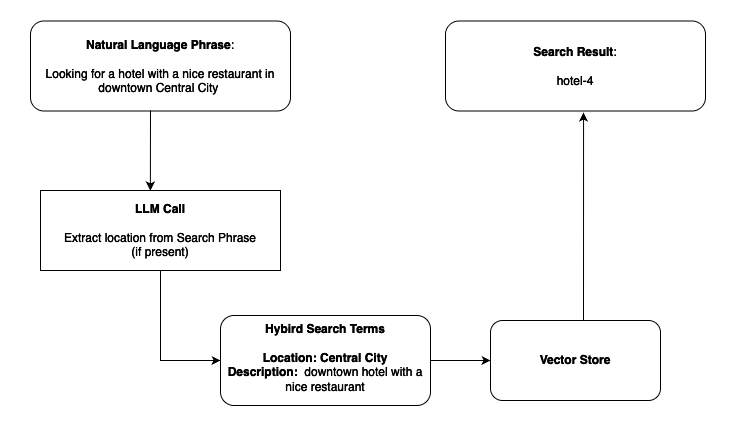
Fine-tune Qwen models in SageMaker JumpStart using RLVR for agent tool calling.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The RLVR (Reinforcement Learning from Verifiable Rewards) approach specifically addresses the 'hallucination of tool arguments' by penalizing models that generate syntactically correct but semantically invalid function calls.
- •The implementation leverages SageMaker's serverless inference endpoints to optimize cost-efficiency for agentic workloads that exhibit bursty, non-continuous traffic patterns.
- •The training pipeline utilizes Qwen 2.5 7B's native support for structured output, which significantly reduces the overhead of post-processing and parsing during the reward calculation phase.
📊 Competitor Analysis▸ Show
| Feature | AWS SageMaker RLVR (Qwen 2.5) | Google Vertex AI Agent Builder | Azure AI Foundry (Model Catalog) |
|---|---|---|---|
| Tool Calling Fine-Tuning | Native RLVR support | Managed RLHF/SFT | Managed SFT |
| Deployment | Serverless/Real-time | Serverless | Serverless/Managed |
| Primary Model Focus | Open Weights (Qwen/Llama) | Gemini Pro/Flash | GPT-4o/Phi-3 |
| Pricing Model | Per-second compute/inference | Per-request/token | Per-token/instance |
🛠️ Technical Deep Dive
- Reward Function Architecture: Employs a multi-stage reward model where Stage 1 validates JSON schema compliance, Stage 2 verifies argument existence against the tool definition, and Stage 3 executes the tool in a sandboxed environment to validate output correctness.
- Training Infrastructure: Utilizes SageMaker Training Jobs with distributed data parallelism, specifically configured for low-latency reward feedback loops during the RLVR process.
- Inference Optimization: The serverless deployment utilizes AWS Lambda-backed inference containers with pre-warmed cold-start mitigation for the Qwen 2.5 7B model weights.
- Dataset Structure: Uses a triplet format (System Prompt, Tool Definitions, User Query) mapped to a Chain-of-Thought (CoT) reasoning path to improve tool selection accuracy.
🔮 Future ImplicationsAI analysis grounded in cited sources
RLVR will become the industry standard for agentic fine-tuning over traditional SFT.
The ability to provide verifiable feedback during training significantly reduces the error rate in complex multi-step tool-use scenarios compared to static supervised datasets.
Serverless inference will dominate agentic deployment architectures by 2027.
The intermittent nature of agentic tool-calling workloads makes provisioned throughput cost-prohibitive compared to event-driven serverless scaling.
⏳ Timeline
2024-09
Alibaba Cloud releases Qwen 2.5 series with enhanced instruction following and tool-use capabilities.
2025-02
AWS introduces native support for Reinforcement Learning from Verifiable Rewards (RLVR) in SageMaker.
2025-11
AWS expands SageMaker serverless inference to support larger model weights, enabling 7B-parameter model hosting.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates



AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗