Rosetta Neurons Exhibit Divergent Selectivity with Model Scale

💡Discover how universal 'Rosetta Neurons' can optimize your data filtering and improve model interpretability.
⚡ 30-Second TL;DR
What Changed
Rosetta Neurons scale as a sublinear power law, occupying a smaller fraction of total neurons in larger models.
Why It Matters
This research provides a pathway for more efficient model training by leveraging specific neurons for high-quality data selection. It deepens the understanding of model interpretability and internal feature representation.
What To Do Next
Explore the provided GitHub repository to test if Rosetta Neurons can improve your model's data filtering pipeline during pretraining.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Rosetta Neurons are identified via cross-model activation mapping, where researchers align latent spaces across architectures to isolate neurons that activate for identical semantic concepts regardless of training data or initialization.
- •The sublinear scaling behavior suggests that as models grow, the 'universal' feature set becomes more compressed, potentially indicating that larger models develop more efficient, high-level abstractions for common linguistic or visual patterns.
- •The data filtering capability leverages these neurons as 'semantic probes,' allowing for the automated removal of low-quality or irrelevant training samples without requiring human-labeled datasets or expensive compute-heavy classifiers.
🛠️ Technical Deep Dive
- Identification Process: Utilizes Procrustes alignment or Canonical Correlation Analysis (CCA) to map activation vectors between a reference model and target models of varying scales.
- Monosemanticity Metric: Measured using the Sparse Autoencoder (SAE) reconstruction error, where Rosetta Neurons show lower interference from polysemantic features in larger models.
- Filtering Mechanism: Implements a threshold-based activation gate on the identified Rosetta Neuron; if the neuron's activation exceeds a specific percentile during a forward pass, the data sample is classified as high-utility.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
Same topic
Explore #interpretability
Same product
More on rosetta-neurons
Same source
Latest from Reddit r/MachineLearning
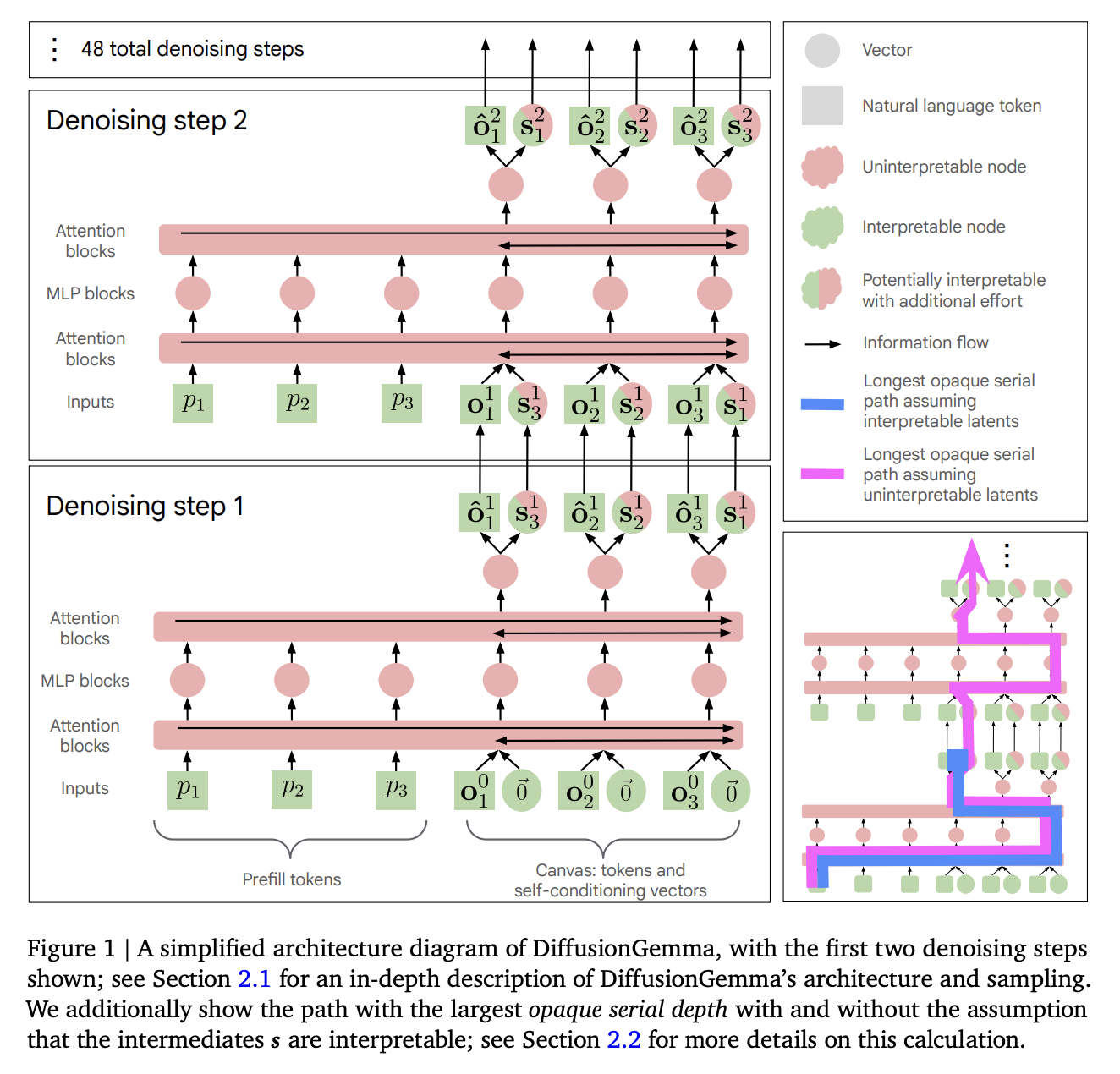
Transparency Audit of Google's DiffusionGemma Model
Seeking ML/Data Collaborator for Portfolio Projects
Evaluating Python packages for PSO and Genetic Algorithms

Simplified PyTorch implementation of FLUX diffusion models
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Reddit r/MachineLearning ↗