☁️AWS Machine Learning Blog•Stalecollected in 2m
Ring Scales Global Support with Bedrock KBs
#customer-story#scaling#knowledge-baseamazon-bedrock-knowledge-basesringamazon-bedrock-knowledge-bases
💡Ring's Bedrock KB scaling cuts costs for global support—blueprint for enterprise AI ops
⚡ 30-Second TL;DR
What Changed
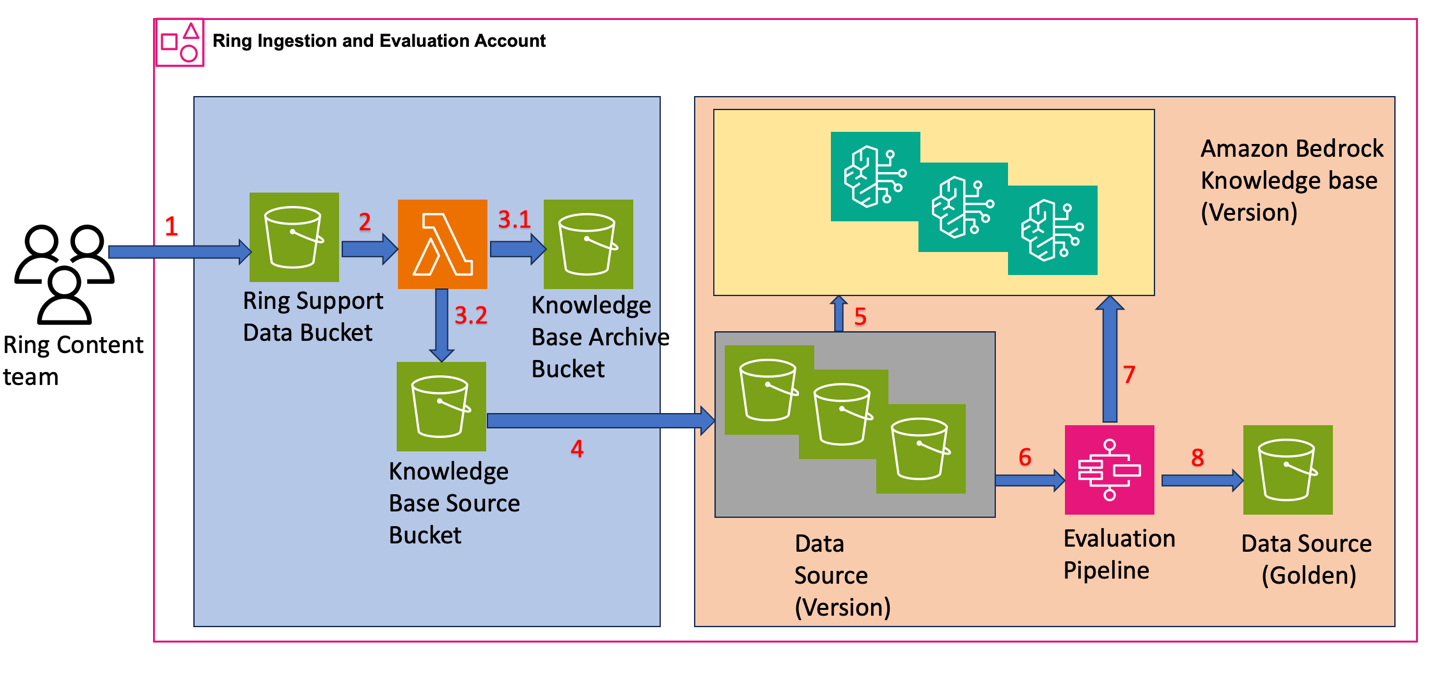
Metadata-driven filtering for region-specific content
Why It Matters
Demonstrates practical scaling of AI knowledge bases for enterprise customer support, reducing costs and improving efficiency across regions.
What To Do Next
Set up metadata filtering in your Bedrock Knowledge Base for multi-region content delivery.
Who should care:Enterprise & Security Teams
Key Points
- •Metadata-driven filtering for region-specific content
- •Separated workflows: ingestion, evaluation, promotion
- •Cost savings achieved while scaling global support
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Ring utilized Amazon Bedrock's Knowledge Bases to reduce the latency of RAG (Retrieval-Augmented Generation) pipelines by implementing a tiered retrieval strategy that prioritizes localized metadata.
- •The architecture leverages Amazon OpenSearch Serverless as the underlying vector store, allowing Ring to manage multi-tenant data isolation without provisioning dedicated infrastructure for each region.
- •By decoupling the ingestion pipeline from the inference layer, Ring successfully mitigated the 'noisy neighbor' effect, ensuring that high-volume support queries in one region do not degrade the performance of RAG applications in another.
📊 Competitor Analysis▸ Show
| Feature | Amazon Bedrock Knowledge Bases | Google Vertex AI Search | Azure AI Search |
|---|---|---|---|
| Vector Store Integration | Native (OpenSearch Serverless) | Native (Vertex Vector Search) | Native (Azure AI Search) |
| Metadata Filtering | Advanced (Attribute-based) | Moderate (Metadata-based) | Advanced (Filter expressions) |
| Deployment Model | Fully Managed RAG | Fully Managed RAG | Fully Managed RAG |
| Pricing Model | Consumption-based (Storage/CU) | Consumption-based (Node/Query) | Consumption-based (RU/Storage) |
🛠️ Technical Deep Dive
- Metadata-Driven Filtering: Implemented via Amazon Bedrock's
filterparameter in theRetrieveAPI, allowing for precise scoping of vector searches based on region-specific tags (e.g.,region: 'EU',language: 'DE'). - Workflow Decoupling:
- Ingestion: Uses AWS Lambda to trigger document processing and vector embedding via Bedrock's Titan Embeddings models.
- Evaluation: Automated testing suite validates retrieval accuracy against a golden dataset before promoting to production.
- Promotion: CI/CD pipeline updates the metadata tags in the OpenSearch index to make content visible to specific regional endpoints.
- Data Isolation: Achieved through logical partitioning within a single OpenSearch Serverless collection, avoiding the overhead of multiple cluster management.
🔮 Future ImplicationsAI analysis grounded in cited sources
Enterprises will shift from monolithic RAG architectures to metadata-partitioned, multi-tenant vector databases.
The success of Ring's approach demonstrates that granular metadata control is more cost-effective and scalable than maintaining separate infrastructure per region.
Automated evaluation workflows will become a standard requirement for production-grade RAG systems.
Ring's explicit separation of evaluation from ingestion highlights the industry's move toward rigorous quality assurance in generative AI pipelines.
⏳ Timeline
2023-09
Amazon Bedrock becomes generally available, introducing Knowledge Bases for RAG.
2024-05
Amazon Bedrock adds support for advanced metadata filtering in Knowledge Bases.
2025-11
Ring completes the migration of its global support documentation to the Bedrock-based RAG architecture.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗