☁️AWS Machine Learning Blog•Stalecollected in 23m
RLAIF Fine-Tuning with LLM-as-a-Judge on Nova
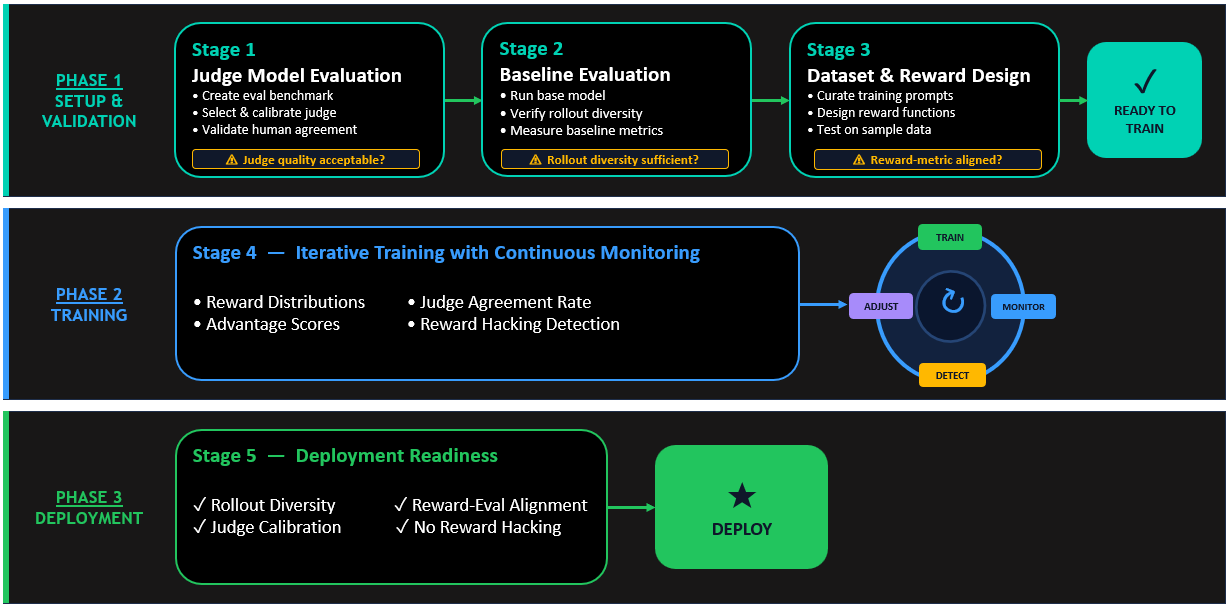
💡Master RLAIF for cost-effective Nova fine-tuning without human judges
⚡ 30-Second TL;DR
What Changed
Explains RLAIF mechanics with LLM-as-a-judge
Why It Matters
Helps AI practitioners align Nova models without costly human feedback, potentially improving model quality and scalability on AWS.
What To Do Next
Experiment with RLAIF on Amazon Nova via AWS SageMaker JumpStart.
Who should care:Developers & AI Engineers
Key Points
- •Explains RLAIF mechanics with LLM-as-a-judge
- •Details application to Amazon Nova models
- •Offers insights for effective implementation on AWS
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Amazon Nova's RLAIF implementation leverages a 'Constitutional AI' framework, allowing developers to define specific behavioral principles that the LLM-as-a-judge uses to score outputs, reducing reliance on human-labeled preference datasets.
- •The integration utilizes Amazon Bedrock's managed infrastructure to automate the iterative feedback loop, significantly lowering the computational overhead typically associated with generating large-scale preference datasets for RLHF.
- •Empirical results on Nova models demonstrate that RLAIF-tuned variants show improved performance on domain-specific reasoning tasks compared to standard supervised fine-tuning, particularly in scenarios where human expert data is scarce or expensive.
📊 Competitor Analysis▸ Show
| Feature | Amazon Nova (RLAIF) | Google Vertex AI (RLAIF) | OpenAI (RLHF/RLAIF) |
|---|---|---|---|
| Primary Mechanism | Constitutional AI/Bedrock | Vertex AI Agent Builder | Custom RLHF/O1-style RL |
| Pricing Model | Bedrock consumption-based | Vertex AI usage-based | API/Token-based |
| Benchmarking | AWS-proprietary benchmarks | MMLU/HumanEval focus | Internal/Open-source mix |
🛠️ Technical Deep Dive
- Feedback Loop Architecture: The process employs a two-stage pipeline where a 'Judge' model (typically a larger Nova variant) evaluates the 'Student' model's responses against a set of provided constitutional principles.
- Reward Modeling: Instead of training a separate reward model, the system uses the Judge's scalar scores or preference rankings directly to compute the policy gradient update during the reinforcement learning phase.
- Data Efficiency: The implementation supports 'synthetic data augmentation,' where the Judge model generates rationales for its preferences, which are then used to train the Student model via chain-of-thought distillation.
- Infrastructure: The workflow is orchestrated via Amazon SageMaker pipelines, enabling automated checkpointing and evaluation of the Student model at each iteration of the RL process.
🔮 Future ImplicationsAI analysis grounded in cited sources
RLAIF will become the standard for enterprise-grade model alignment by 2027.
The scalability and cost-efficiency of automated feedback loops will render manual human-in-the-loop RLHF unsustainable for rapidly evolving enterprise model requirements.
Model-generated rationales will replace static preference labels in training datasets.
Providing the model with the 'why' behind a preference score significantly improves reasoning capabilities compared to simple binary or scalar feedback.
⏳ Timeline
2024-12
AWS announces the Amazon Nova foundation model family.
2025-03
Amazon Bedrock introduces native support for automated model evaluation workflows.
2026-02
AWS releases enhanced RLAIF toolkits for Amazon Nova on Bedrock.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗