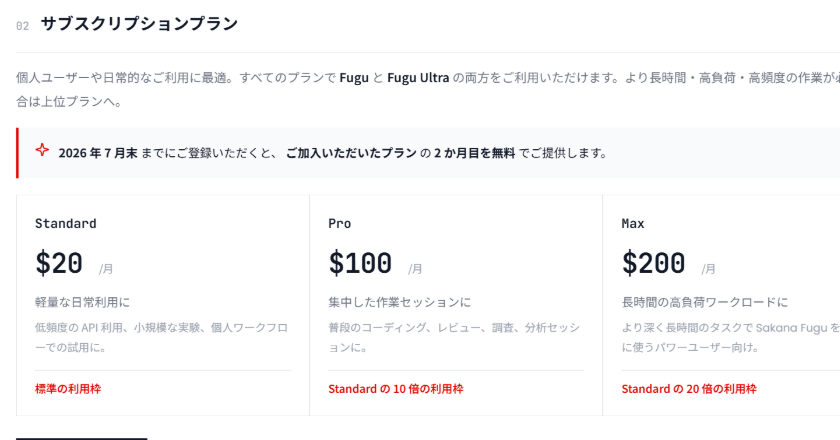
PFN Launches PLaMo 3.0 Prime with Free API Plan
💡New Japanese full-scratch model with a free API tier—worth testing for localized LLM applications.
⚡ 30-Second TL;DR
What Changed
PLaMo 3.0 Prime is a full-scratch AI model developed by Preferred Networks.
Why It Matters
This release provides a new localized alternative for Japanese AI applications, potentially challenging global models in specific regional tasks. The free API tier lowers the barrier for local developers to integrate native Japanese language capabilities.
What To Do Next
Sign up for the PLaMo API and benchmark its performance against GPT-4o or Claude 3.5 on your specific Japanese language tasks.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •PLaMo 3.0 Prime utilizes a Mixture-of-Experts (MoE) architecture to optimize inference speed while maintaining high parameter efficiency.
- •The model was trained on a proprietary, high-quality Japanese-centric dataset, specifically curated to outperform Western-centric models in Japanese cultural and linguistic nuance.
- •Preferred Networks integrated PLaMo 3.0 Prime directly into their MN-Core supercomputing infrastructure, significantly reducing the energy consumption required for training and fine-tuning.
- •The free API tier is subject to rate limits and is primarily intended for non-commercial research and prototyping, with enterprise-grade SLAs reserved for paid tiers.
- •PLaMo 3.0 Prime features an extended context window of 128k tokens, enabling the processing of long-form technical documentation and complex Japanese legal contracts.
📊 Competitor Analysis▸ Show
| Feature | PLaMo 3.0 Prime | GPT-4o (OpenAI) | Claude 3.5 Sonnet (Anthropic) |
|---|---|---|---|
| Primary Focus | Japanese Linguistic Nuance | General Purpose / Multimodal | Reasoning / Coding |
| Architecture | MoE (Full-Scratch) | Dense/MoE (Proprietary) | Dense (Proprietary) |
| API Pricing | Free Tier / Competitive | Usage-based | Usage-based |
| Context Window | 128k | 128k | 200k |
🛠️ Technical Deep Dive
- Architecture: Mixture-of-Experts (MoE) design with sparse activation to balance performance and latency.
- Training Infrastructure: Leverages PFN's proprietary MN-Core hardware accelerators.
- Context Window: Supports up to 128,000 tokens for long-context tasks.
- Language Focus: Optimized for Japanese syntax, honorifics, and domain-specific terminology in manufacturing and research.
- Deployment: Available via REST API with support for standard OpenAI-compatible client libraries.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: ITmedia AI+ (日本) ↗