💰钛媒体•Freshcollected in 13h
DeepSeek stability improvements explained in new paper
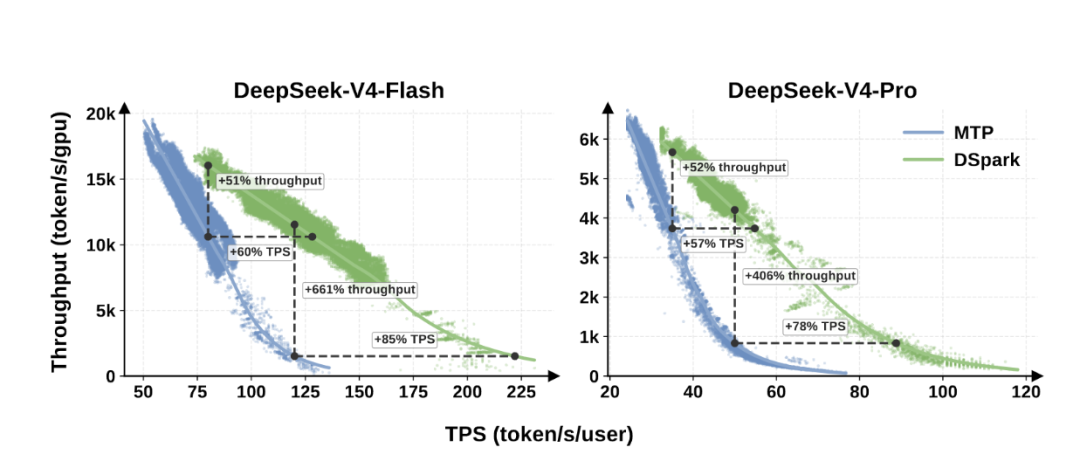
💡DeepSeek reveals the technical secrets behind fixing their model stability issues in a new paper.
⚡ 30-Second TL;DR
What Changed
DeepSeek stability issues resolved
Why It Matters
Understanding DeepSeek's optimization techniques helps developers improve the reliability and efficiency of their own LLM deployments.
What To Do Next
Read the latest DeepSeek research paper to apply their stability optimization techniques to your own LLM serving stack.
Who should care:Researchers & Academics
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The stability improvements primarily address 'loss spikes' and 'gradient explosion' issues encountered during the training of DeepSeek's Mixture-of-Experts (MoE) architectures.
- •The research paper introduces a novel 'Auxiliary-Loss-Free' load balancing strategy that prevents expert collapse without sacrificing model convergence speed.
- •DeepSeek implemented a specialized 'FP8 mixed-precision training' framework that reduces memory overhead while maintaining numerical stability during large-scale distributed training.
- •The optimization strategy includes a dynamic token routing mechanism that mitigates communication bottlenecks across GPU clusters, a common cause of instability in massive MoE models.
- •The paper details a 'warm-up' scheduling technique specifically designed for high-parameter models to stabilize the initial phases of training where divergence is most frequent.
📊 Competitor Analysis▸ Show
| Feature | DeepSeek (MoE) | GPT-4o (Dense) | Claude 3.5 (Dense) |
|---|---|---|---|
| Architecture | Mixture-of-Experts | Dense Transformer | Dense Transformer |
| Inference Efficiency | High (Sparse Activation) | Moderate | Moderate |
| Training Stability | Improved (via new paper) | Proprietary | Proprietary |
| Cost-to-Performance | Industry Leading | Premium | Premium |
🛠️ Technical Deep Dive
- Implementation of a novel load balancing algorithm that eliminates the need for auxiliary loss terms, preventing the 'expert collapse' phenomenon.
- Utilization of FP8 quantization techniques to optimize memory bandwidth and reduce communication latency between nodes.
- Introduction of a dynamic routing protocol that adjusts expert selection based on real-time token complexity, reducing computational variance.
- Refinement of the gradient clipping and normalization layers to handle the high-variance nature of sparse model updates.
- Adoption of a multi-stage training schedule that stabilizes weight initialization and prevents early-stage divergence in large-scale clusters.
🔮 Future ImplicationsAI analysis grounded in cited sources
DeepSeek will achieve faster training convergence cycles compared to dense model competitors.
The removal of auxiliary loss and optimized routing allows for more efficient parameter utilization and reduced computational waste.
The open-sourcing of these stability techniques will accelerate the adoption of MoE architectures in enterprise-grade LLMs.
By solving the primary stability hurdles, DeepSeek lowers the barrier to entry for other organizations attempting to train large-scale sparse models.
⏳ Timeline
2024-01
DeepSeek releases its first major open-source MoE model, signaling a shift toward sparse architectures.
2024-05
DeepSeek-V2 launch introduces significant advancements in Multi-head Latent Attention (MLA).
2025-02
DeepSeek-V3 is released, showcasing improved training efficiency and scale.
2026-05
Publication of the research paper detailing new stability and load-balancing optimizations.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: 钛媒体 ↗