🐼Pandaily•Freshcollected in 2h
China AI API Calls Lead Globally for Nine Weeks
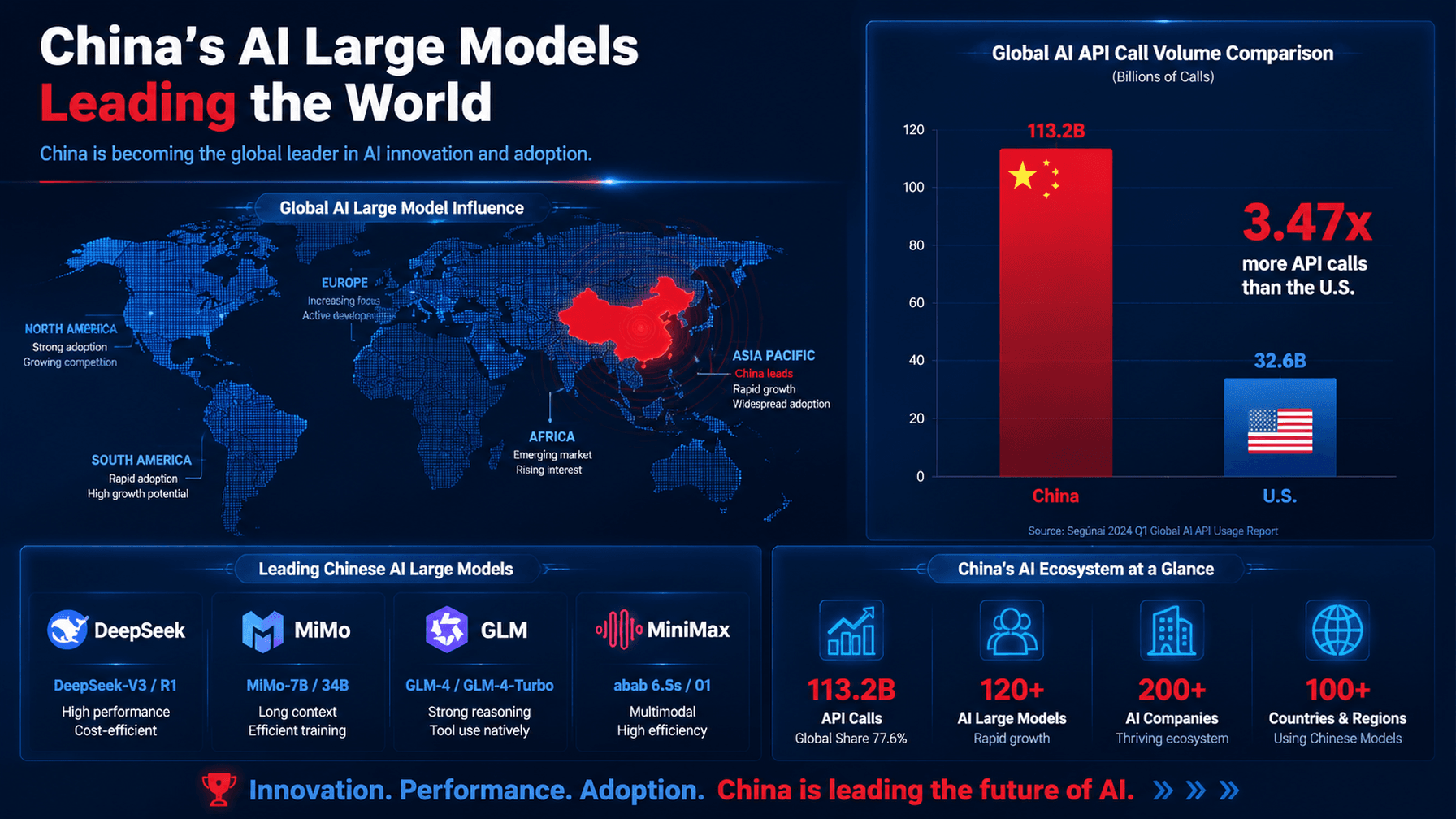
💡China's AI API dominance is surging; see which models are driving the shift from US-centric tools.
⚡ 30-Second TL;DR
What Changed
DeepSeek-V4-Flash, MiMo-V2.5, and MiniMax M3 are the top-performing models.
Why It Matters
This shift indicates a rapid acceleration in the adoption of Chinese LLMs, potentially challenging the dominance of US-based providers in global developer ecosystems.
What To Do Next
Evaluate the performance of DeepSeek-V4-Flash and MiniMax M3 against your current LLM stack to see if they offer better latency or cost-efficiency.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The surge in Chinese API volume is largely attributed to aggressive price wars, with major providers reducing inference costs by over 90% compared to early 2025 levels.
- •Integration of these models into domestic super-apps and IoT ecosystems has created a high-frequency usage floor that US-based enterprise-focused models currently lack.
- •Regulatory shifts in China have prioritized 'Model-as-a-Service' (MaaS) infrastructure, incentivizing developers to utilize domestic APIs for compliance and latency advantages.
- •The decline in US market share is partially linked to the 'Great Firewall' latency overhead and increasing geopolitical restrictions on cross-border data flow for AI training.
- •DeepSeek and MiniMax have pioneered 'Mixture-of-Experts' (MoE) optimizations specifically tuned for low-resource hardware, significantly lowering the barrier to entry for small-to-medium enterprises.
📊 Competitor Analysis▸ Show
| Feature | DeepSeek-V4-Flash | MiniMax M3 | OpenAI GPT-5o | Anthropic Claude 3.5 Opus |
|---|---|---|---|---|
| Architecture | Sparse MoE | Multimodal MoE | Dense/Hybrid | Dense |
| Pricing (per 1M tokens) | $0.05 | $0.08 | $2.50 | $3.00 |
| Latency (TTFT) | Ultra-Low | Low | Moderate | Moderate |
| Primary Market | Global/Cost-Sensitive | Domestic/Consumer | Enterprise/Global | Enterprise/Coding |
🛠️ Technical Deep Dive
- DeepSeek-V4-Flash utilizes a novel 'Deep-Cache' mechanism that reduces KV cache memory footprint by 40% during long-context inference.
- MiMo-V2.5 employs a dynamic routing algorithm that activates only 5% of total parameters per token, optimizing for throughput on consumer-grade GPUs.
- MiniMax M3 architecture integrates native audio-to-audio processing, bypassing the need for separate ASR/TTS pipelines, which reduces end-to-end latency by 200ms.
🔮 Future ImplicationsAI analysis grounded in cited sources
US-based AI firms will pivot to 'Edge-First' deployment models to regain market share.
The high latency of centralized cloud APIs in international markets necessitates local processing to compete with the efficiency of Chinese API providers.
Global AI pricing will reach a 'commodity floor' by Q4 2026.
The ongoing price war between Chinese providers and US incumbents is rapidly eroding profit margins, forcing a shift toward value-added services rather than raw token sales.
⏳ Timeline
2025-03
DeepSeek releases V3, initiating the aggressive pricing strategy in the Chinese market.
2025-09
MiniMax launches M3, focusing on native multimodal capabilities for mobile integration.
2026-02
Chinese government releases updated guidelines favoring domestic AI infrastructure for public sector projects.
2026-04
DeepSeek-V4-Flash is deployed, marking the start of the nine-week dominance in API call volume.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗