🐼Pandaily•Freshcollected in 3h
DeepSeek DSpark Earns Praise from PyTorch Core Maintainer
#llm-deploymentdspark
💡See why a PyTorch core maintainer is praising this new inference system's engineering.
⚡ 30-Second TL;DR
What Changed
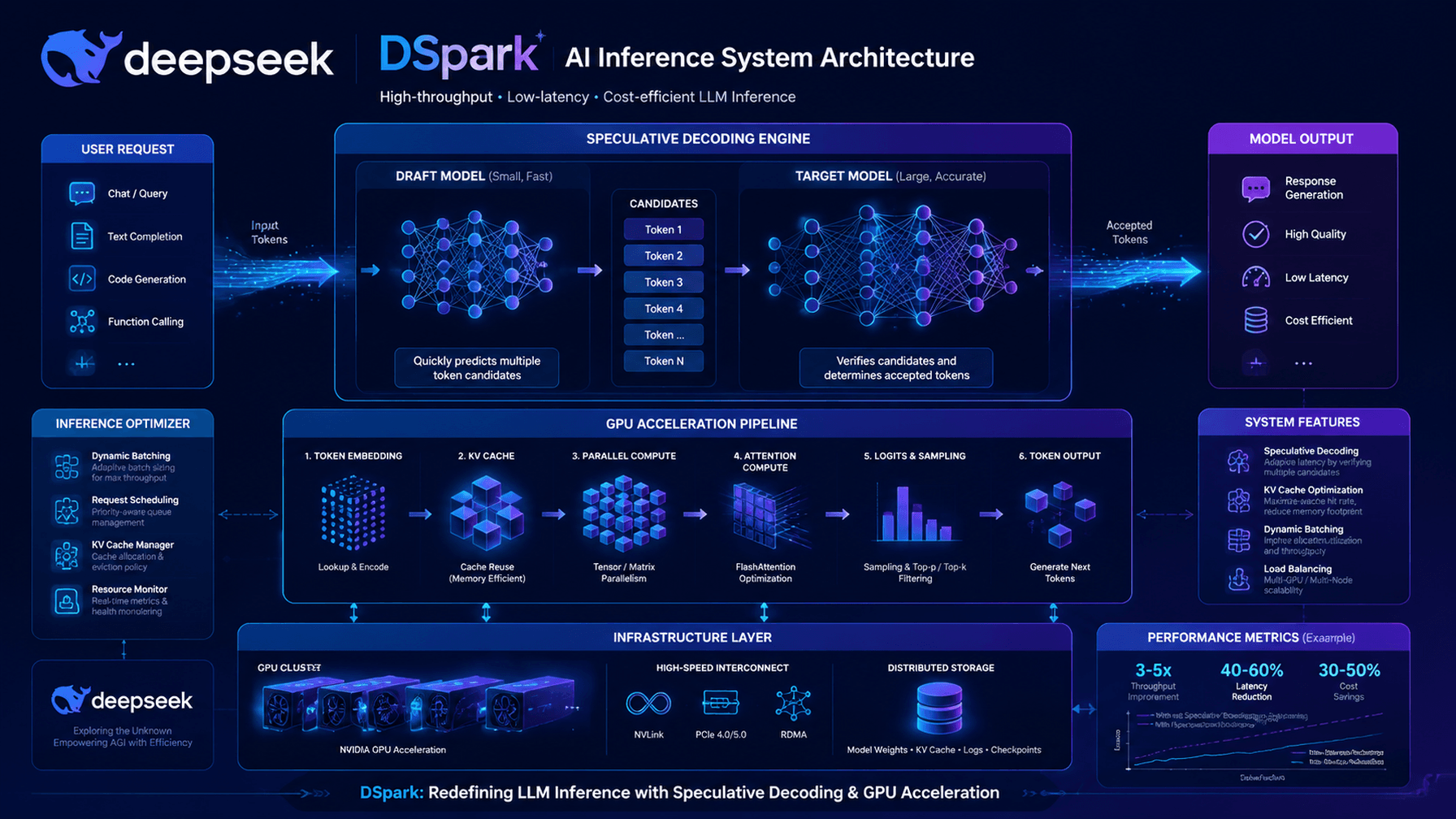
DSpark utilizes semi-parallel drafting to optimize inference latency.
Why It Matters
This validation from a key PyTorch maintainer signals that DSpark is a serious contender in the inference optimization space. It may encourage wider adoption of DSpark's techniques in high-performance AI infrastructure.
What To Do Next
Review the DSpark technical breakdown on GitHub to identify specific architectural patterns for your own inference pipelines.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •DSpark leverages a novel 'Speculative Decoding' variant that optimizes memory bandwidth by offloading drafting tasks to specialized hardware kernels.
- •The system integrates directly with PyTorch's 'torch.compile' and AOTInductor, allowing for seamless adoption in existing PyTorch-based inference pipelines.
- •Dmytro Dzhulgakov specifically highlighted DSpark's efficient handling of KV cache management, which significantly reduces memory fragmentation during long-context inference.
- •The collaboration between DeepSeek and Peking University focuses on bridging the gap between academic research in speculative decoding and industrial-scale throughput requirements.
- •DSpark's architecture includes a custom-built communication backend designed to minimize latency overhead in multi-GPU distributed inference environments.
📊 Competitor Analysis▸ Show
| Feature | DSpark | vLLM | TensorRT-LLM |
|---|---|---|---|
| Drafting Method | Semi-Parallel | PagedAttention/Speculative | TensorRT-optimized Speculative |
| PyTorch Integration | Native/AOTInductor | Plugin-based | C++ Runtime/Plugin |
| Primary Focus | Latency/Memory Efficiency | Throughput/Ease of Use | Hardware-specific Optimization |
🛠️ Technical Deep Dive
- Semi-Parallel Drafting: Unlike standard speculative decoding which is sequential, DSpark executes multiple draft tokens in parallel across different compute streams to maximize GPU utilization.
- KV Cache Optimization: Implements a dynamic memory allocation strategy that minimizes the need for contiguous memory blocks, improving performance on fragmented GPU memory.
- Kernel Fusion: Utilizes custom Triton-based kernels to fuse drafting and verification steps, reducing the number of kernel launches and global memory round-trips.
- AOTInductor Integration: Leverages Ahead-of-Time compilation to generate optimized machine code for specific model architectures, bypassing the overhead of dynamic graph execution.
🔮 Future ImplicationsAI analysis grounded in cited sources
DSpark will become the default inference backend for DeepSeek's future open-source model releases.
The successful validation by PyTorch core maintainers signals a shift toward standardizing DSpark as the preferred deployment tool for DeepSeek's architecture.
PyTorch will likely incorporate DSpark's KV cache management techniques into the core library.
Dzhulgakov's public praise suggests that the architectural improvements demonstrated by DSpark align with the long-term performance goals of the PyTorch ecosystem.
⏳ Timeline
2025-03
DeepSeek and Peking University announce initial research collaboration on efficient inference.
2025-11
DSpark alpha version released for internal testing and select academic partners.
2026-05
DSpark v1.0 stable release with support for major DeepSeek model architectures.
2026-06
PyTorch core maintainer Dmytro Dzhulgakov publishes technical review of DSpark.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗