💼VentureBeat•Freshcollected in 8m
AWS Quick Desktop Agent Builds Personal Knowledge Graph

💡Desktop agent with personal KG enables proactive actions, but risks shadow orchestration in enterprises
⚡ 30-Second TL;DR
What Changed
Desktop-native agent with continuous knowledge graph from local files and SaaS integrations
Why It Matters
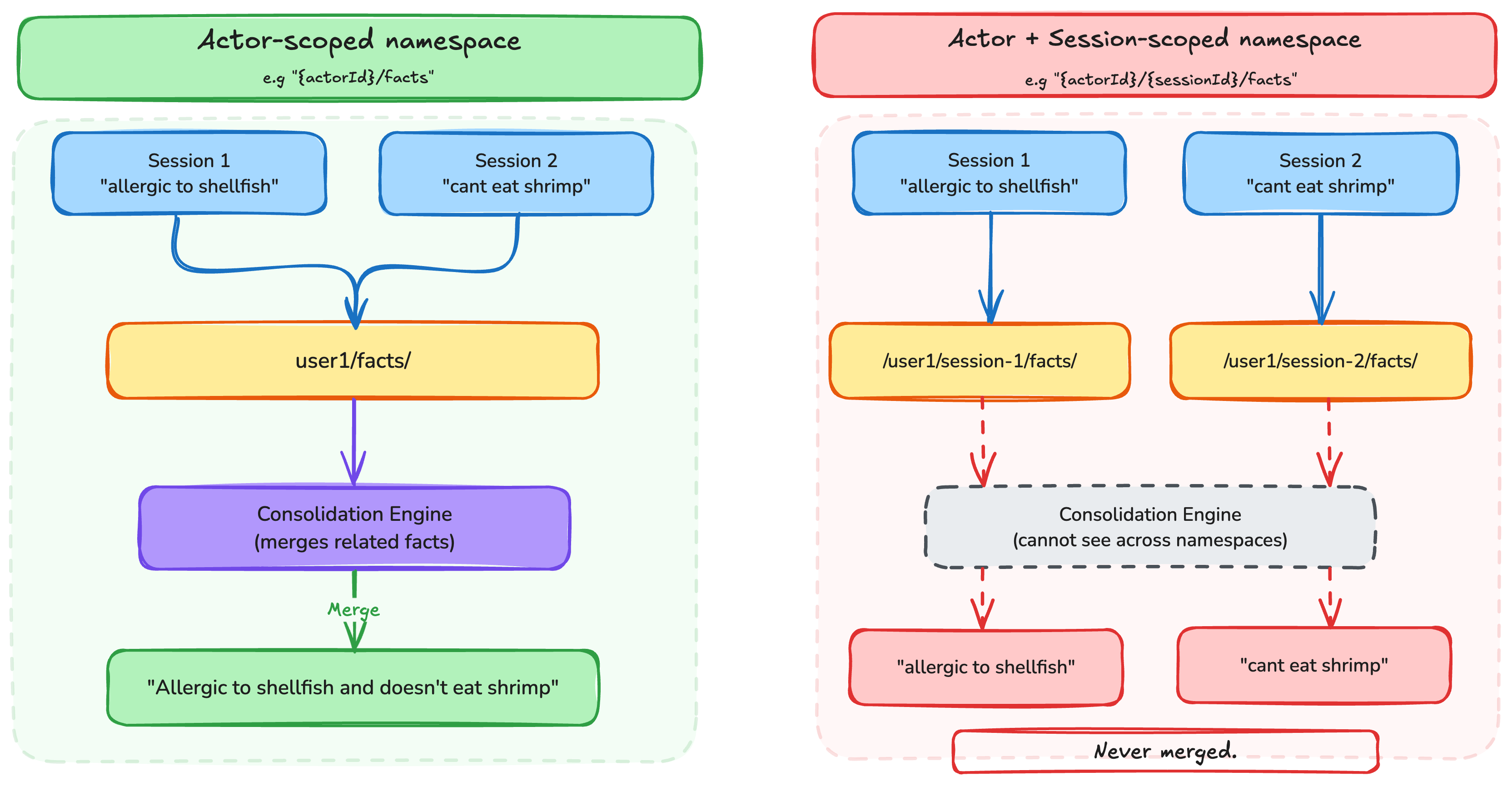
Enterprises gain proactive personal agents but must address visibility gaps in orchestration layers. AI teams may need updated governance for user-specific knowledge graphs, balancing autonomy and control.
What To Do Next
Test AWS Quick's desktop agent integrations with your SaaS tools like Slack and Google Workspace.
Who should care:Enterprise & Security Teams
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •AWS Quick utilizes a local-first vector database architecture, ensuring that sensitive PII and enterprise documents are indexed on the user's machine rather than being transmitted to a centralized AWS cloud training cluster.
- •The agent employs a 'Human-in-the-Loop' (HITL) override mechanism where enterprise IT administrators can define 'Action Guardrails' to restrict the agent's ability to execute specific API calls (e.g., deleting records or sending external emails) without explicit user confirmation.
- •The system leverages a proprietary 'Contextual Reranking Engine' that prioritizes information based on temporal proximity and interaction frequency, distinguishing it from standard RAG (Retrieval-Augmented Generation) implementations that rely solely on semantic similarity.
📊 Competitor Analysis▸ Show
| Feature | AWS Quick Desktop Agent | Microsoft Copilot Pro | Notion AI Agent |
|---|---|---|---|
| Knowledge Graph | Persistent, cross-app local graph | Cloud-based, M365-centric | Workspace-specific |
| Shadow Orchestration | High (Proactive local actions) | Low (Managed by IT policies) | Low (App-contained) |
| Pricing | Enterprise per-seat licensing | $20/user/month | Included in Plus/Enterprise |
| Benchmarks | High latency local inference | Low latency cloud inference | Low latency cloud inference |
🛠️ Technical Deep Dive
- •Architecture: Employs a hybrid model utilizing a lightweight local LLM (based on a quantized version of Amazon Titan) for real-time intent classification and a cloud-based model for complex reasoning.
- •Data Ingestion: Uses a local file system watcher (inotify/FSEvents) to maintain a real-time index of local documents, which are converted into embeddings via a local embedding model.
- •Security: Implements end-to-end encryption for the local knowledge graph database, with keys managed by AWS KMS (Key Management Service) integrated with enterprise identity providers.
- •Orchestration: Utilizes a custom 'Action-Graph' framework that maps natural language intents to specific SaaS API endpoints via OAuth 2.0 scoped tokens.
🔮 Future ImplicationsAI analysis grounded in cited sources
Enterprise IT departments will mandate 'Agent Auditing' software to monitor local knowledge graph activity.
The shift toward proactive, local-first orchestration creates a visibility gap that traditional network-level security tools cannot bridge.
AWS will introduce a 'Federated Knowledge' feature allowing enterprise-wide graph sharing.
The current siloed nature of personal knowledge graphs limits the potential for organizational intelligence, necessitating a secure, opt-in aggregation layer.
⏳ Timeline
2025-03
AWS announces the initial 'Quick' cloud-based productivity suite.
2025-11
AWS releases the Quick API for third-party SaaS integration.
2026-04
AWS launches the Quick Desktop Agent with persistent local knowledge graph capabilities.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: VentureBeat ↗