AI Agent Evaluation Framework for AutoML
💡New EA audits AutoML agent decisions (F1 0.919), uncovers hidden errors outcome metrics miss.
⚡ 30-Second TL;DR
What Changed
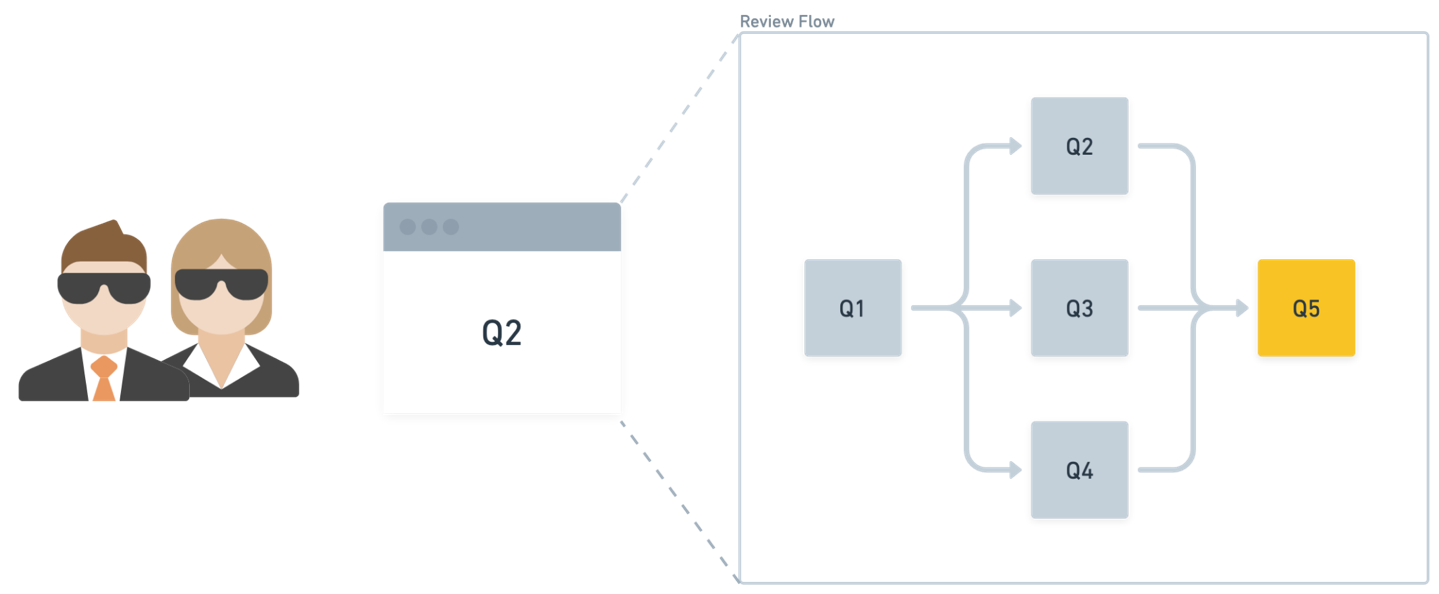
Proposes observer-style Evaluation Agent (EA) for post-hoc decision assessment
Why It Matters
Shifts AutoML agent evaluation from outcomes to decisions, enhancing interpretability and governance. Helps practitioners build trustworthy AI systems by identifying subtle errors early. Foundation for scalable, reliable agentic ML pipelines.
What To Do Next
Download arXiv:2602.22442v1 and prototype EA to audit decisions in your AutoML agents.
🧠 Deep Insight
Web-grounded analysis with 6 cited sources.
🔑 Enhanced Key Takeaways
- •The paper 'Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems' (arXiv:2512.12791) proposes an end-to-end framework with four pillars—LLMs, Memory, Tools, and Environment—validated on Autonomous CloudOps use cases to capture runtime uncertainties overlooked by task completion metrics[1].
- •AEMA (arXiv:2601.11903) uses a multi-agent system that plans, debates, and aggregates judgments for verifiable evaluations of agentic LLM workflows, achieving superior stability and human alignment compared to single LLM-as-a-Judge approaches in enterprise scenarios[2][4].
- •Recent discourse (arXiv:2602.03238) highlights challenges in agent benchmarks due to confounding factors like prompts and environments, advocating a unified standardization to ensure reproducible and fair evaluations[3].
📊 Competitor Analysis▸ Show
| Framework | Key Features | Benchmarks | Pricing |
|---|---|---|---|
| EA (Article) | Post-hoc observer for AutoML; validity, consistency, risks, counterfactuals | F1=0.919 fault detection; -4.9% to +8.3% attribution | Open research (arXiv) |
| Agent Assessment (arXiv:2512.12791) | Four pillars: LLMs/Memory/Tools/Environment; end-to-end | Behavioral deviations in CloudOps | Open research (arXiv) |
| AEMA (arXiv:2601.11903) | Multi-agent planning/debating; human oversight; traceable logs | Stability/human alignment in enterprise workflows | Open research (arXiv) |
🛠️ Technical Deep Dive
- •AEMA employs coordinated multi-agent evaluators that plan multi-step assessments, execute domain-specific/general functions outputting normalized 0-1 scores with qualitative feedback, and aggregate via a Final Report Agent for enterprise workflows[2][4].
- •Agent Assessment Framework validates on Autonomous CloudOps, examining tool invocation, memory retrieval, agent collaboration, and environment interaction to address non-determinism[1].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (6)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: ArXiv AI ↗