💰钛媒体•Stalecollected in 67m
What AI Leaderboards Truly Compete For
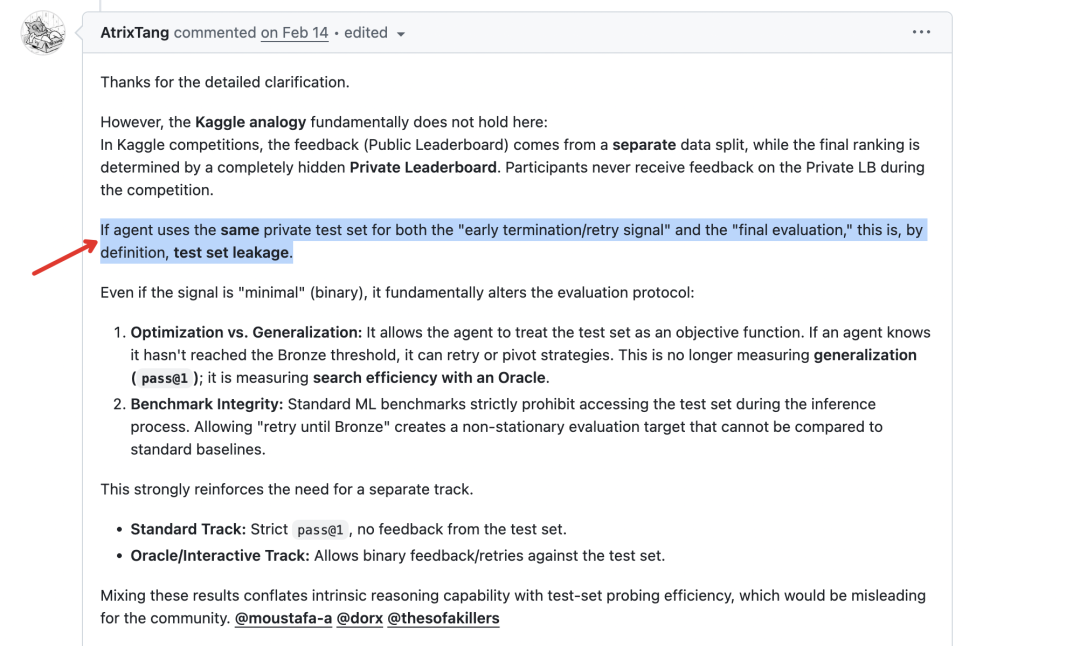
💡Unpacks what 'winning' AI leaderboards really tests
⚡ 30-Second TL;DR
What Changed
AI leaderboards require self-cultivation
Why It Matters
Challenges how practitioners view benchmarks, promoting more nuanced model evaluations.
What To Do Next
Cross-validate top leaderboard models on custom benchmarks before deployment.
Who should care:Researchers & Academics
Key Points
- •AI leaderboards require self-cultivation
- •Beyond surface-level benchmark beating
- •Metaphor for robust ranking methodologies
- •Critique of AI evaluation standards
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The proliferation of 'Goodhart's Law' in AI evaluation, where benchmarks like MMLU or GSM8K lose their predictive power as models are increasingly trained on test-set data (data contamination).
- •The emergence of 'LLM-as-a-judge' frameworks, such as MT-Bench or AlpacaEval, which attempt to capture subjective human preference but introduce new biases related to model length and style over factual accuracy.
- •The industry shift toward 'dynamic' or 'private' evaluation sets that are inaccessible to developers during training, aiming to mitigate the gaming of public leaderboards.
🔮 Future ImplicationsAI analysis grounded in cited sources
Static public benchmarks will become obsolete for frontier model evaluation by 2027.
The rapid saturation of existing benchmarks due to data contamination necessitates a move toward proprietary, continuously updated evaluation environments.
Evaluation-as-a-Service (EaaS) will become a primary revenue stream for independent AI research labs.
As trust in self-reported model performance declines, third-party, audited evaluation platforms will gain significant market leverage.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates




AI-curated news aggregator. All content rights belong to original publishers.
Original source: 钛媒体 ↗