🛡️Cloudflare Blog•Stalecollected in 3h
Unweight Compresses LLMs 22% Losslessly
💡22% LLM compression w/o quality loss—slash inference costs on edge now!
⚡ 30-Second TL;DR
What Changed
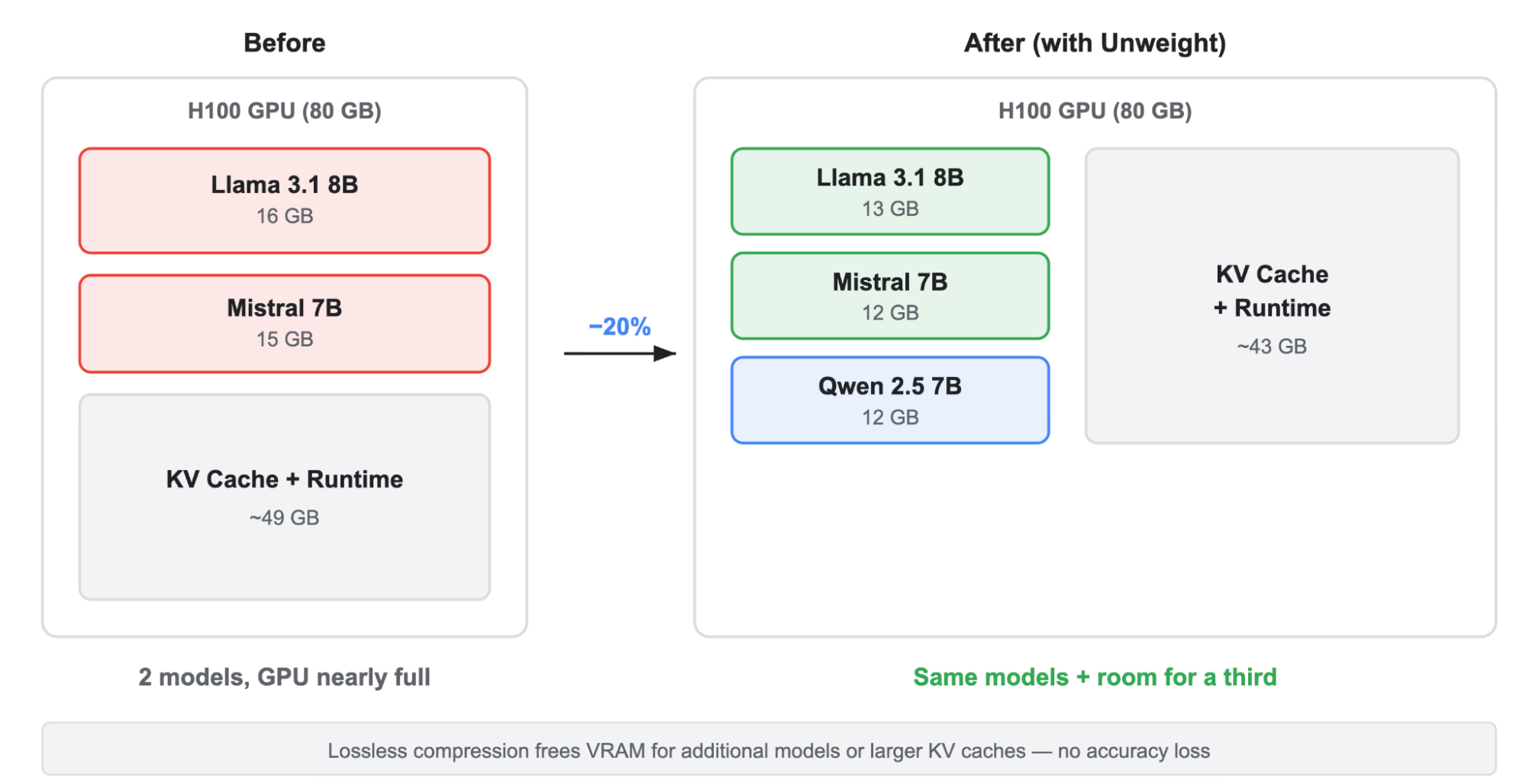
Achieves 22% model footprint reduction losslessly
Why It Matters
Enables efficient deployment of larger LLMs on edge networks, cutting inference costs and latency for AI services. Benefits developers scaling AI apps globally.
What To Do Next
Test Unweight via Cloudflare Workers AI for 22% faster LLM inference.
Who should care:Developers & AI Engineers
Key Points
- •Achieves 22% model footprint reduction losslessly
- •Inference-time compression preserves full quality
- •Targets GPU memory bandwidth for Cloudflare network
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Unweight leverages a novel entropy-coding scheme specifically optimized for the weight distribution patterns found in Transformer-based architectures, allowing for rapid decompression directly into GPU registers.
- •The system is designed to integrate seamlessly with Cloudflare's Workers AI platform, enabling dynamic model loading across distributed edge nodes without the latency penalties typically associated with large model transfers.
- •By reducing memory bandwidth bottlenecks, Unweight allows Cloudflare to increase the concurrency of inference requests per GPU, directly improving the cost-efficiency of their serverless AI offerings.
📊 Competitor Analysis▸ Show
| Feature | Unweight (Cloudflare) | NVIDIA TensorRT-LLM | vLLM (PagedAttention) |
|---|---|---|---|
| Primary Focus | Lossless footprint reduction | Kernel-level optimization | Memory management/throughput |
| Compression Type | Lossless (Entropy-based) | Quantization (Lossy) | N/A (Memory scheduling) |
| Deployment | Edge/Distributed | Data Center/Cloud | Data Center/Cloud |
| Benchmark Focus | Bandwidth efficiency | Latency/Throughput | Request concurrency |
🛠️ Technical Deep Dive
- •Utilizes a two-stage decompression pipeline: a lightweight hardware-accelerated entropy decoder followed by a just-in-time (JIT) weight reconstruction kernel.
- •Operates on model weights at the tensor level, specifically targeting FP16/BF16 weight matrices to identify and compress redundant bit-patterns without altering numerical precision.
- •Implements a custom caching layer that maintains decompressed weight blocks in high-speed SRAM, minimizing trips to VRAM during the forward pass.
- •Compatible with standard model formats (e.g., Safetensors), requiring no retraining or fine-tuning of the original model weights.
🔮 Future ImplicationsAI analysis grounded in cited sources
Cloudflare will expand Unweight to support lossy compression modes for non-critical inference tasks.
The current lossless architecture provides a foundation for high-ratio quantization techniques that could further reduce memory footprints for edge-constrained devices.
Unweight will become a standard feature for all models hosted on Cloudflare Workers AI by Q4 2026.
The significant reduction in bandwidth costs and improved concurrency metrics provide a strong economic incentive for universal adoption across their infrastructure.
⏳ Timeline
2025-09
Cloudflare announces initial research into edge-optimized model compression techniques.
2026-02
Internal beta testing of Unweight begins on select Workers AI production clusters.
2026-04
Official public announcement and deployment of Unweight across the global Cloudflare network.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: Cloudflare Blog ↗