🔥PyTorch Blog•Stalecollected in 21m
torch.compile Hits SOTA Normalization Speed
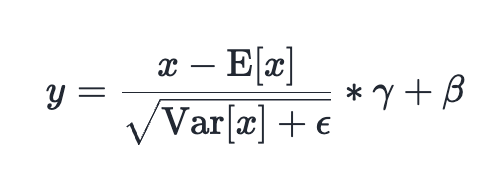
💡SOTA speedups for norm layers via torch.compile – optimize your DL training now.
⚡ 30-Second TL;DR
What Changed
SOTA performance in LayerNorm and RMSNorm
Why It Matters
Faster normalization boosts training efficiency for large models, reducing compute costs for practitioners.
What To Do Next
Apply torch.compile to your LayerNorm layers and benchmark performance gains.
Who should care:Developers & AI Engineers
Key Points
- •SOTA performance in LayerNorm and RMSNorm
- •Enabled by torch.compile optimization
- •Improves smoothness in deep learning training
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The optimization leverages Triton-based kernel fusion, allowing PyTorch to automatically generate specialized GPU kernels for normalization layers that outperform manually written CUDA implementations.
- •Performance gains are particularly pronounced in transformer-based architectures where LayerNorm and RMSNorm are invoked repeatedly across deep stacks, reducing memory bandwidth bottlenecks.
- •This advancement is part of a broader effort to move PyTorch's core library toward a 'compiler-first' architecture, reducing the reliance on eager-mode execution for production-grade inference and training.
📊 Competitor Analysis▸ Show
| Feature | PyTorch (torch.compile) | JAX (jit/pjit) | TensorFlow (XLA) |
|---|---|---|---|
| Compilation Backend | Inductor (Triton/OpenAI) | XLA | XLA |
| Ease of Use | High (Drop-in decorator) | Moderate (Functional paradigm) | Moderate (Graph mode) |
| Normalization Speed | SOTA (Kernel Fusion) | High (XLA Fusion) | High (XLA Fusion) |
| Ecosystem Integration | Native Python/PyTorch | Functional/Pure | Graph-based |
🛠️ Technical Deep Dive
- •Implementation utilizes the PyTorch Inductor compiler backend to perform operator fusion, collapsing multiple normalization sub-operations (mean, variance, scale, shift) into a single GPU kernel launch.
- •Reduces global memory access by keeping intermediate tensors in SRAM (shared memory) during the normalization pass.
- •Supports both static and dynamic input shapes, maintaining performance parity even when batch sizes or sequence lengths vary during training.
- •Leverages Triton's ability to handle complex memory coalescing patterns, which is critical for the high-dimensional tensor operations found in modern LLMs.
🔮 Future ImplicationsAI analysis grounded in cited sources
Normalization layers will become a negligible cost in total training time.
As kernel fusion techniques mature, the overhead of memory-bound operations like LayerNorm will be effectively hidden by compute-bound operations.
Manual CUDA kernel writing will become obsolete for standard deep learning layers.
The performance gap between auto-generated Triton kernels and hand-optimized CUDA is closing, favoring the maintainability of compiler-based approaches.
⏳ Timeline
2022-12
PyTorch 2.0 announced with torch.compile as the primary feature.
2023-03
PyTorch 2.0 officially released, introducing the Inductor compiler backend.
2024-05
PyTorch 2.3 introduces significant improvements to Triton integration and kernel fusion capabilities.
2025-09
PyTorch 2.5 expands compiler support for complex dynamic shapes and advanced normalization patterns.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗