🔥PyTorch Blog•Stalecollected in 12m
TorchAO Extends QAT for Edge LLMs
💡Unlock extended QAT in TorchAO for compact LLMs on edge devices.
⚡ 30-Second TL;DR
What Changed
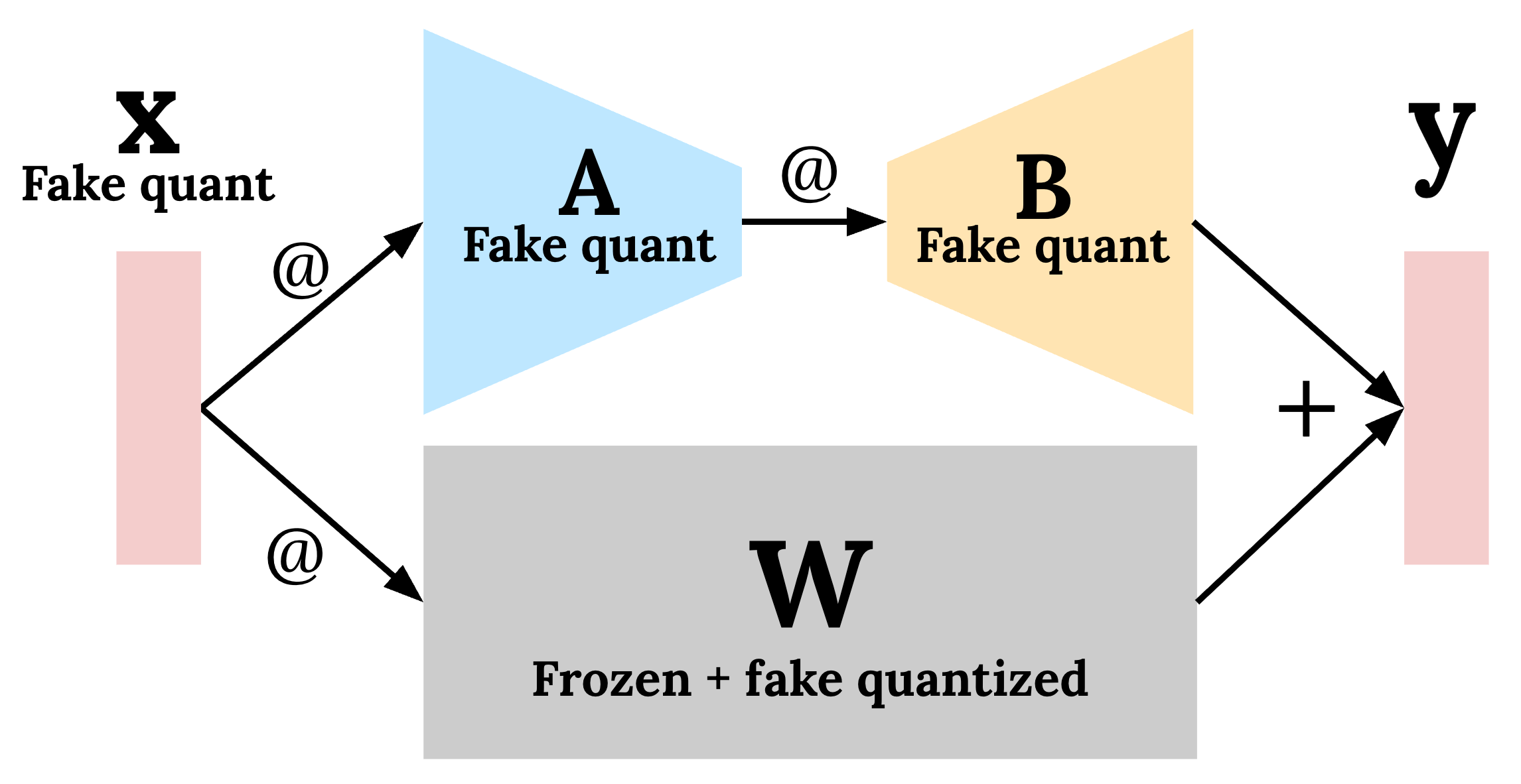
Extended QAT flow in TorchAO for LLMs
Why It Matters
This enables more efficient LLM deployment on edge hardware, reducing model size and inference latency for mobile and IoT AI apps.
What To Do Next
Experiment with TorchAO's extended QAT in PyTorch to optimize your LLM for ExecuTorch edge export.
Who should care:Developers & AI Engineers
🧠 Deep Insight
Web-grounded analysis with 7 cited sources.
🔑 Enhanced Key Takeaways
- •TorchAO's QAT supports int8 dynamic per-token activations + int4 grouped per-channel weights (8da4w) for linear layers, motivated by kernel availability on edge backends and optimal LLM quality[4][6].
- •QAT in TorchAO recovers 96% of accuracy degradation on Hellaswag and 68% of perplexity degradation on WikiText for Llama3 compared to PTQ[4][6].
- •QAT workflow uses prepare step to insert fake quantization ops into linear layers during training, followed by convert step to replace with actual quantize/dequantize ops for inference[4][6].
🛠️ Technical Deep Dive
- •QATConfig with Int8DynamicActivationInt4WeightConfig (group_size=32) applied via torchao.quantization.quantize_ in two steps: 'prepare' inserts fake quantize ops, 'convert' finalizes to actual quantized layers[6].
- •Supports combination with LoRA for 1.89x faster training compared to vanilla QAT[6].
- •Fake quantization simulates rounding to low-bit values (e.g., staying in bfloat16) during training, enabling model adaptation to quantization constraints[1][3].
🔮 Future ImplicationsAI analysis grounded in cited sources
ExecuTorch QAT extension will enable 4-bit LLMs on mobile with <2% accuracy loss
Building on demonstrated 96% PTQ recovery for Llama3 and seamless ExecuTorch export workflows shown in Unsloth collaboration.
TorchAO QAT + LoRA will reduce edge LLM fine-tuning time by >1.8x
GitHub documentation confirms 1.89x speedup over vanilla QAT using established fine-tuning recipes.
⏳ Timeline
2024-07
Initial TorchAO QAT prototype introduced under torchao prototype module
2024-10
PyTorch blog announces end-to-end QAT flow for LLMs with torchao APIs and Llama3 benchmarks
2025-01
Torchao GitHub adds QAT README, LoRA+QAT recipes, and ExecuTorch deployment support
2026-03
TorchAO extends QAT flow specifically for edge LLMs targeting ExecuTorch runtime
📎 Sources (7)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗