☁️AWS Machine Learning Blog•Stalecollected in 10m
Speculative Decoding Boosts LLM Inference
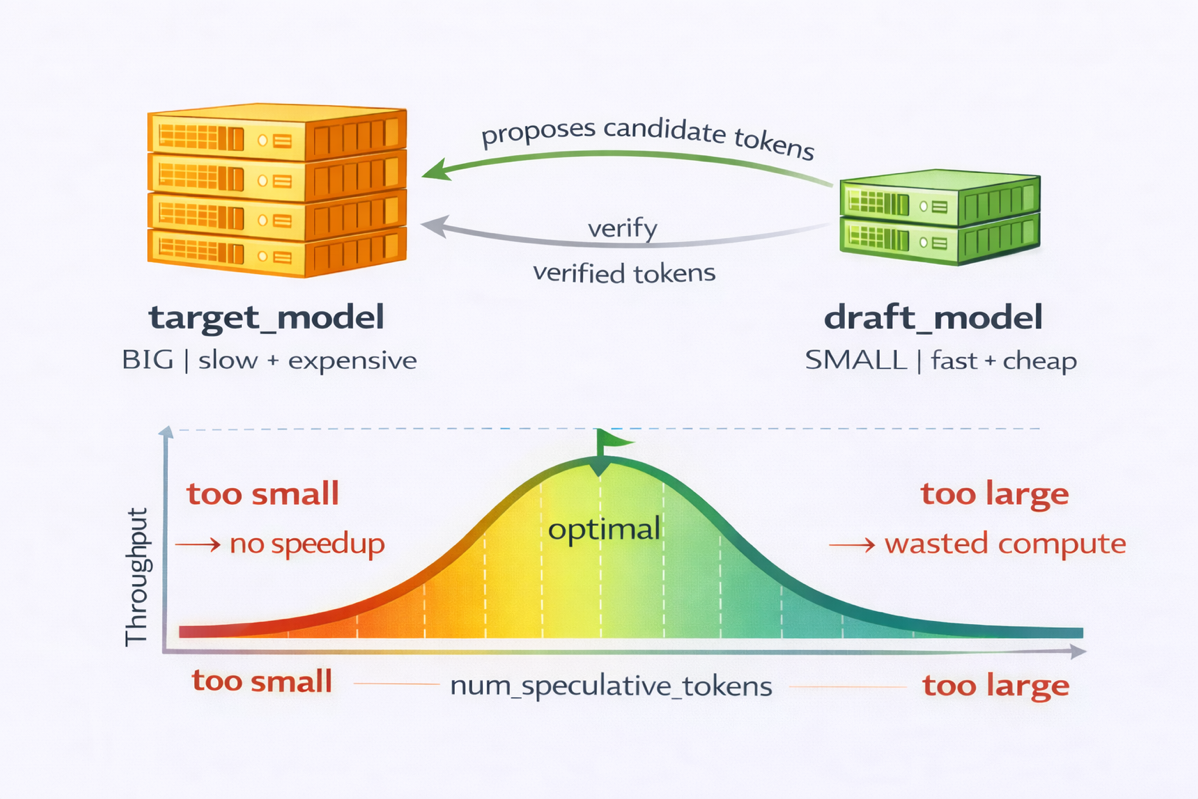
💡Cut LLM token costs 2x+ via speculative decoding on Trainium2 + vLLM
⚡ 30-Second TL;DR
What Changed
Speculative decoding optimizes decode-heavy LLM inference
Why It Matters
Lowers inference costs for production LLMs on Trainium2. Enables faster, cheaper deployments for AI practitioners scaling generative AI apps.
What To Do Next
Deploy vLLM with speculative decoding on Trainium2 to cut LLM inference costs.
Who should care:Developers & AI Engineers
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗