🐼Pandaily•Stalecollected in 13m
PaddleOCR Tops GitHub OCR Stars Over Tesseract
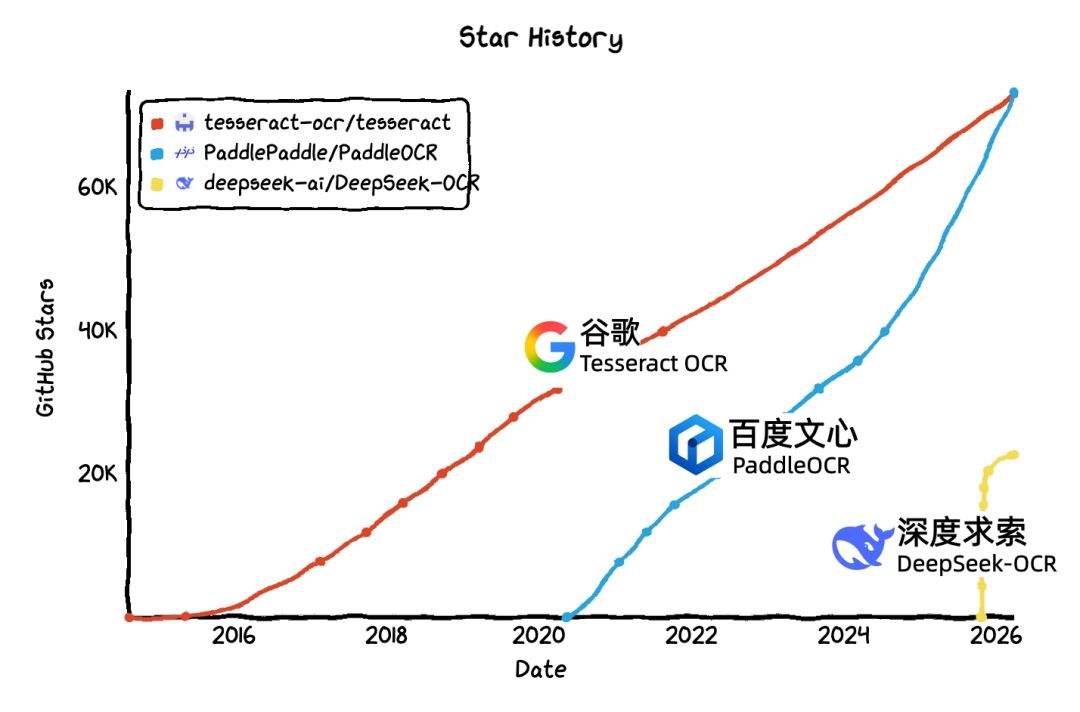
💡Top GitHub OCR now PaddleOCR—Baidu beats Google stars. Devs, switch?
⚡ 30-Second TL;DR
What Changed
Most-starred OCR project on GitHub
Why It Matters
Demonstrates rising dominance of Chinese open-source AI tools in global developer communities, potentially shifting preferences from established Western alternatives like Tesseract.
What To Do Next
Benchmark PaddleOCR against Tesseract for your next document scanning project.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •PaddleOCR's architecture is built on the PaddlePaddle deep learning framework, enabling it to leverage specialized hardware acceleration like Baidu's Kunlun chips for high-throughput inference.
- •The project distinguishes itself from Tesseract by offering a comprehensive 'OCR toolkit' approach, including pre-trained models for specialized tasks like table recognition, layout analysis, and document structure extraction.
- •Unlike Tesseract, which historically relied on traditional image processing and LSTM-based recognition, PaddleOCR utilizes a modular pipeline integrating PP-OCRv4 (or later) models that combine detection, direction classification, and recognition networks for superior performance on complex, multi-lingual scenes.
📊 Competitor Analysis▸ Show
| Feature | PaddleOCR | Tesseract | EasyOCR |
|---|---|---|---|
| Architecture | Deep Learning (PP-OCR) | LSTM / Traditional | Deep Learning (PyTorch) |
| Ease of Use | High (Modular API) | Moderate (CLI/Wrapper) | High (Simple API) |
| Performance | High (Optimized for speed) | Moderate (Accuracy varies) | Moderate |
| Pricing | Open Source (Apache 2.0) | Open Source (Apache 2.0) | Open Source (Apache 2.0) |
| Language Support | Extensive (incl. CJK) | Extensive | Moderate |
🛠️ Technical Deep Dive
- Pipeline Architecture: Utilizes a three-stage pipeline: Text Detection (DBNet), Direction Classification, and Text Recognition (CRNN/SVTR).
- Model Optimization: Employs knowledge distillation, quantization, and pruning to maintain high accuracy while reducing model size for edge deployment.
- Framework Integration: Native integration with PaddlePaddle allows for seamless deployment on mobile devices (Paddle Lite) and server-side (Paddle Inference).
- Multilingual Capability: Supports over 80 languages out-of-the-box, with specific optimizations for Chinese, English, and mixed-script documents.
🔮 Future ImplicationsAI analysis grounded in cited sources
PaddleOCR will increasingly dominate enterprise-grade document automation in the APAC region.
Its superior handling of complex Chinese character layouts and integration with the broader Baidu AI ecosystem provides a significant competitive moat over Western-centric tools.
Tesseract will transition to a legacy maintenance role in the developer ecosystem.
The lack of modern deep learning architecture updates in Tesseract makes it increasingly unsuitable for high-precision, real-world computer vision tasks compared to modular frameworks like PaddleOCR.
⏳ Timeline
2020-06
Baidu officially open-sources the PaddleOCR project on GitHub.
2021-09
Release of PP-OCRv2, significantly improving inference speed and model accuracy.
2022-05
Introduction of PP-OCRv3, featuring enhanced text detection and recognition capabilities.
2023-08
Launch of PP-OCRv4, incorporating advanced techniques like SVTR for better recognition performance.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Pandaily ↗