Oumi Fine-Tunes Llama for Bedrock Deployment
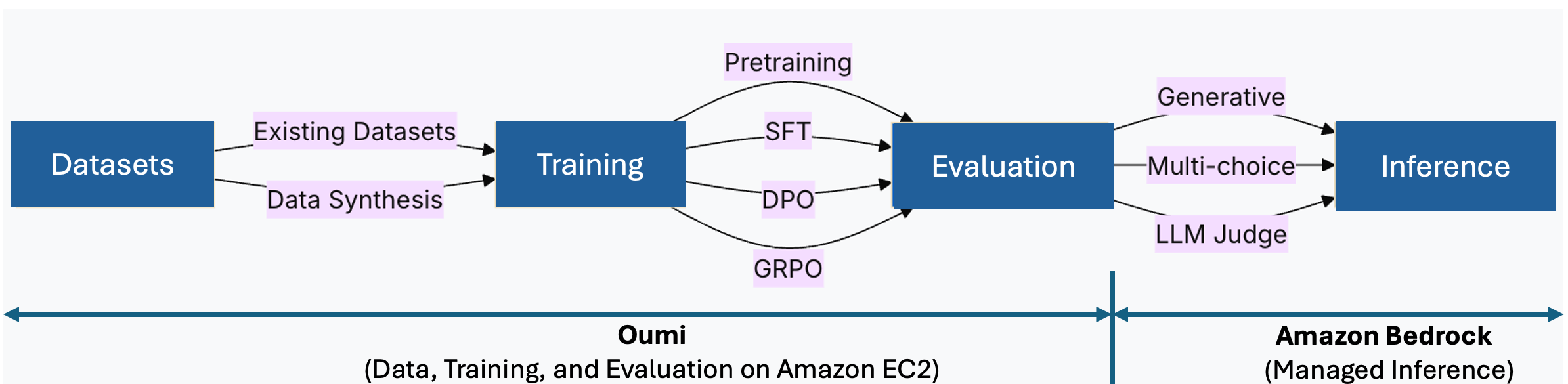
💡Fast-track custom LLM deployment: Oumi fine-tune + Bedrock import workflow.
⚡ 30-Second TL;DR
What Changed
Fine-tune Llama models using Oumi on Amazon EC2 instances
Why It Matters
This workflow accelerates custom LLM deployment, allowing AI practitioners to leverage AWS ecosystem for faster productionization. It reduces barriers to customizing open models like Llama for enterprise use.
What To Do Next
Fine-tune a Llama model with Oumi on EC2 and import it to Amazon Bedrock today.
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
- •Amazon Bedrock introduced on-demand deployment for custom Meta Llama 3.3 models as of September 2025, eliminating the need for pre-provisioned compute resources and enabling pay-per-use pricing models[1].
- •vLLM 0.15.0 and later versions support multi-LoRA inference optimization across MoE model families (GPT-OSS, Qwen3-MoE, DeepSeek, Llama MoE) with Amazon-specific optimizations delivering 19% faster output token throughput and 8% better time-to-first-token latency compared to open-source vLLM[2][5].
- •Amazon Bedrock's fine-tuning infrastructure includes behind-the-scenes optimizations (batch processing, LoRA configuration, prompt masking) that improve fine-tuned model performance by up to 5% compared to open-source fine-tuning recipes, applied automatically without manual configuration[4].
- •Meta Llama 3.2 multimodal fine-tuning on Amazon Bedrock is currently available only in the US West (Oregon) AWS Region as of the latest documentation, with regional expansion ongoing[4].
🛠️ Technical Deep Dive
- •Multi-LoRA serving now supports Mixture-of-Experts (MoE) model families including GPT-OSS, Qwen3-MoE, DeepSeek, and Llama MoE variants[2][5].
- •Speculative decoding with CudaGraph for LoRA was implemented to fix issues where different CudaGraphs were captured for base models versus adapters, reducing GPU kernel overhead[2].
- •An EVEN_K parameter optimization checks whether K divides evenly by BLOCK_SIZE_K to skip masking operations entirely when loads are valid, reducing both masking overhead and unnecessary dot product computations[2].
- •LoRA weight addition was fused with base model weights into the LoRA expand kernel, reducing kernel launch overhead and achieving 144 output tokens per second (OTPS) and 135 ms time-to-first-token (TTFT) for GPT-OSS 20B[2].
- •Fine-tuning jobs require IAM roles with trust relationships allowing Amazon Bedrock assumption, S3 access for training/validation data, S3 write permissions for output artifacts, and optional AWS KMS key decryption permissions[4].
- •Hyperparameter configuration for fine-tuning includes epoch count, batch size, learning rate, and learning rate warmup steps, with customization type specified as FINE_TUNING[7].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- aws.amazon.com — On Demand Deployment Custom Meta Llama Models Amazon Bedrock
- aws.amazon.com — Efficiently Serve Dozens of Fine Tuned Models with Vllm on Amazon Sagemaker AI and Amazon Bedrock
- aws.amazon.com — Fine Tune and Deploy Meta Llama 3 2 Vision for Generative AI Powered Web Automation Using Aws Dlcs Amazon Eks and Amazon Bedrock
- aws.amazon.com — Best Practices for Meta Llama 3 2 Multimodal Fine Tuning on Amazon Bedrock
- blog.vllm.ai — Multi Lora
- youtube.com — Watch
- oneuptime.com — View
- serverlessland.com — Best Practices for Meta Llama 32 Multimodal Fine Tuning on Amazon Bedrock Aws Machine Learning Blog
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗