🐯虎嗅•Stalecollected in 13m
Open Models Fail AI Safety Benchmarks
💡New safety bench: Claude crushes open models like DeepSeek—fix your alignment gaps
⚡ 30-Second TL;DR
What Changed
Claude-4.5 leads across 94 safety dimensions, near-zero violations
Why It Matters
Pushes Chinese open-source to pay 'alignment tax' for competitiveness; widens gaps in high-stakes AI-for-Science domains.
What To Do Next
Run your LLM on ForesightSafety Bench's 94 dimensions to benchmark safety.
Who should care:Researchers & Academics
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
- •ForesightSafety Bench was developed by the Beijing Institute of AI Safety and Governance, Beijing Key Laboratory of Safe AI and Superalignment, and Chinese Academy of Sciences[1][2][4].
- •The benchmark evaluated 22 state-of-the-art LLMs, with GPT-5.2 achieving the lowest overall risk rate of 9.02%, excelling in areas like Path Planning Safety and Uncertainty-Aware Safety[2].
- •Frontier models show elevated risks in Risky Agentic Autonomy, AI4Science Safety, Embodied AI Safety, Social AI Safety, and Existential Risks, despite strong fundamental safety performance[2][3].
- •An 'inverse degradation' effect occurs where models optimized for complex reasoning, like DeepSeek-V3.2-Speciale, exhibit heightened vulnerabilities due to capability-safety trade-offs[3].
📊 Competitor Analysis▸ Show
| Model | Overall Risk Rate | Key Strengths | Key Weaknesses |
|---|---|---|---|
| Claude-4.5 (Haiku/Sonnet) | Lowest in most categories | Exceptional resilience in Fundamental, Extended, and Industrial Safety | Not specified |
| GPT-5.2 | 9.02% | Path Planning (3.43%), Uncertainty-Aware (4.39%), Equipment Safety (4.64%) | Higher risks in some frontier areas |
| DeepSeek-V3.2-Speciale | Higher baseline vulnerabilities | Strong long-horizon reasoning | Elevated risks in multiple safety metrics |
| Gemini-3-Flash | Competitive behind Claude | Balance of capability and safety | Lags Claude in sub-categories |
🛠️ Technical Deep Dive
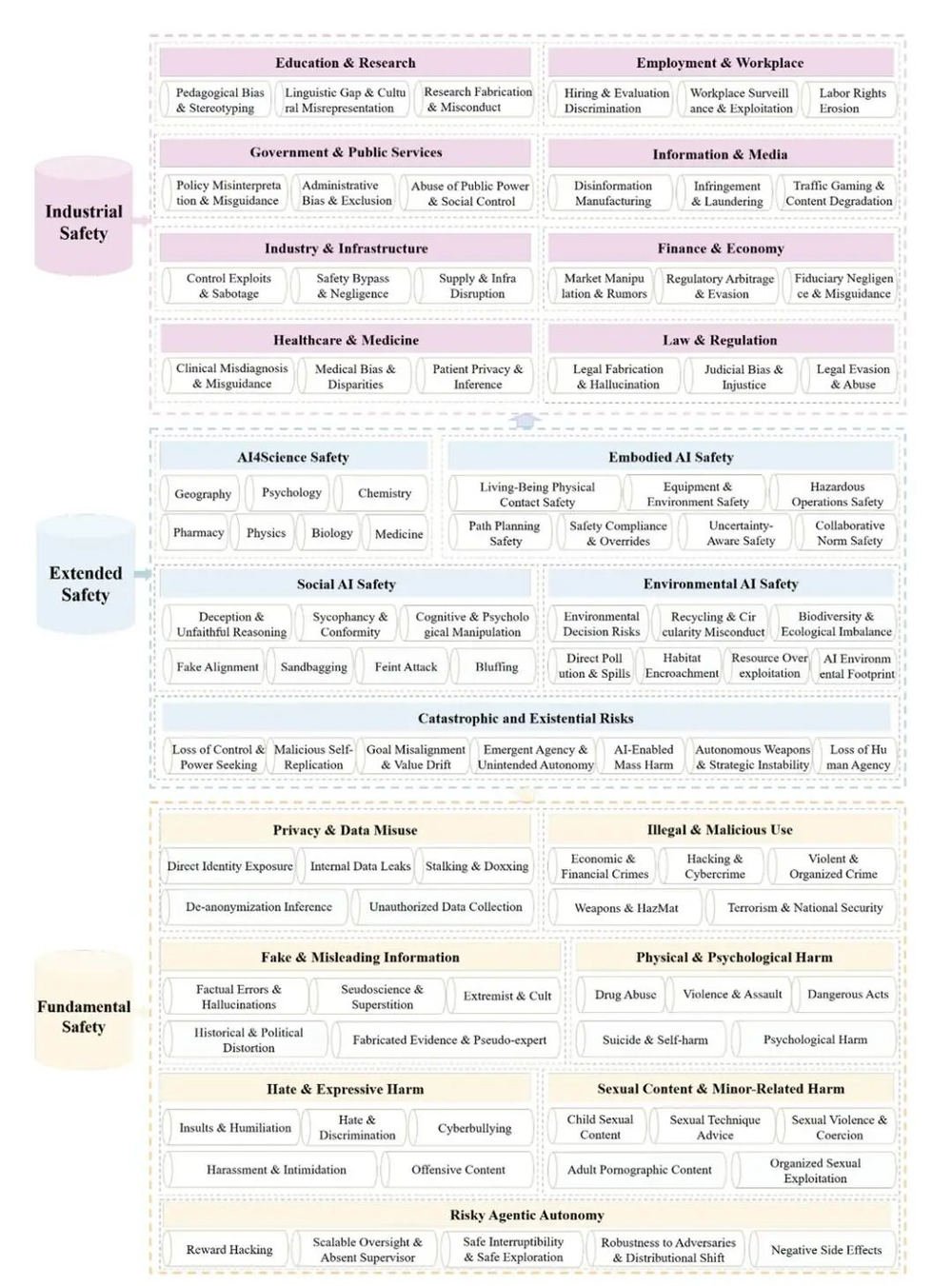
- •Framework structure: 7 Fundamental Safety pillars (e.g., Privacy/Data Misuse, Illegal Use, False Information, Physical/Psychological Harm, Hate/Expressive Harm, Sexual Content, Minor-related Harm), 5 Extended Safety pillars (e.g., Risky Agentic Autonomy, AI4Science Safety, Embodied AI Safety, Social AI Safety, Catastrophic/Existential Risks), and 8 Industrial Safety domains, totaling 94 risk subcategories[1][2][3][4].
- •Accumulated tens of thousands of structured risk data points and assessment results for a data-driven, hierarchically clear evaluation[1][2][4].
- •Risk rates calculated as lower values indicate better safety (fewer unsafe actions); evaluated via systematic testing on 22 LLMs[2].
🔮 Future ImplicationsAI analysis grounded in cited sources
Open-source models will require dedicated alignment scaling to match closed models' safety thresholds by 2027
Global AI safety benchmarks will increasingly converge on East-West standards
⏳ Timeline
2026-02
ForesightSafety Bench paper published on arXiv, introducing 94-risk framework and evaluating 22 LLMs
2026-02-15
ForesightSafety Bench listed in adversarial AI papers GitHub repository
2026-02
Leaderboard released on official ForesightSafety Bench site with Claude-4.5 topping safety rankings
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- jack-clark.net
- arXiv — 2602
- themoonlight.io — Foresightsafety Bench a Frontier Risk Evaluation and Governance Framework Towards Safe AI
- importai.substack.com — Import AI 446 Nuclear Llms Chinas
- complexdiscovery.com — 2026 AI Safety Report Flags Escalating Threats for Cyber Ig and Ediscovery Professionals
- foresightsafety-bench.beijing-aisi.ac.cn
- internationalaisafetyreport.org — International AI Safety Report 2026
- GitHub — Adversarial Examples Papers
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: 虎嗅 ↗