Observability Powers Agent Evaluation
💡Unlock reliable agents: master observability for reasoning insights and eval.
⚡ 30-Second TL;DR
What Changed
Observability reveals how agents reason internally
Why It Matters
Enables practitioners to debug and iterate on agents effectively. Drives better agent performance metrics, accelerating adoption in real-world applications.
What To Do Next
Use LangChain's observability tools to evaluate your agent's reasoning traces before deployment.
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
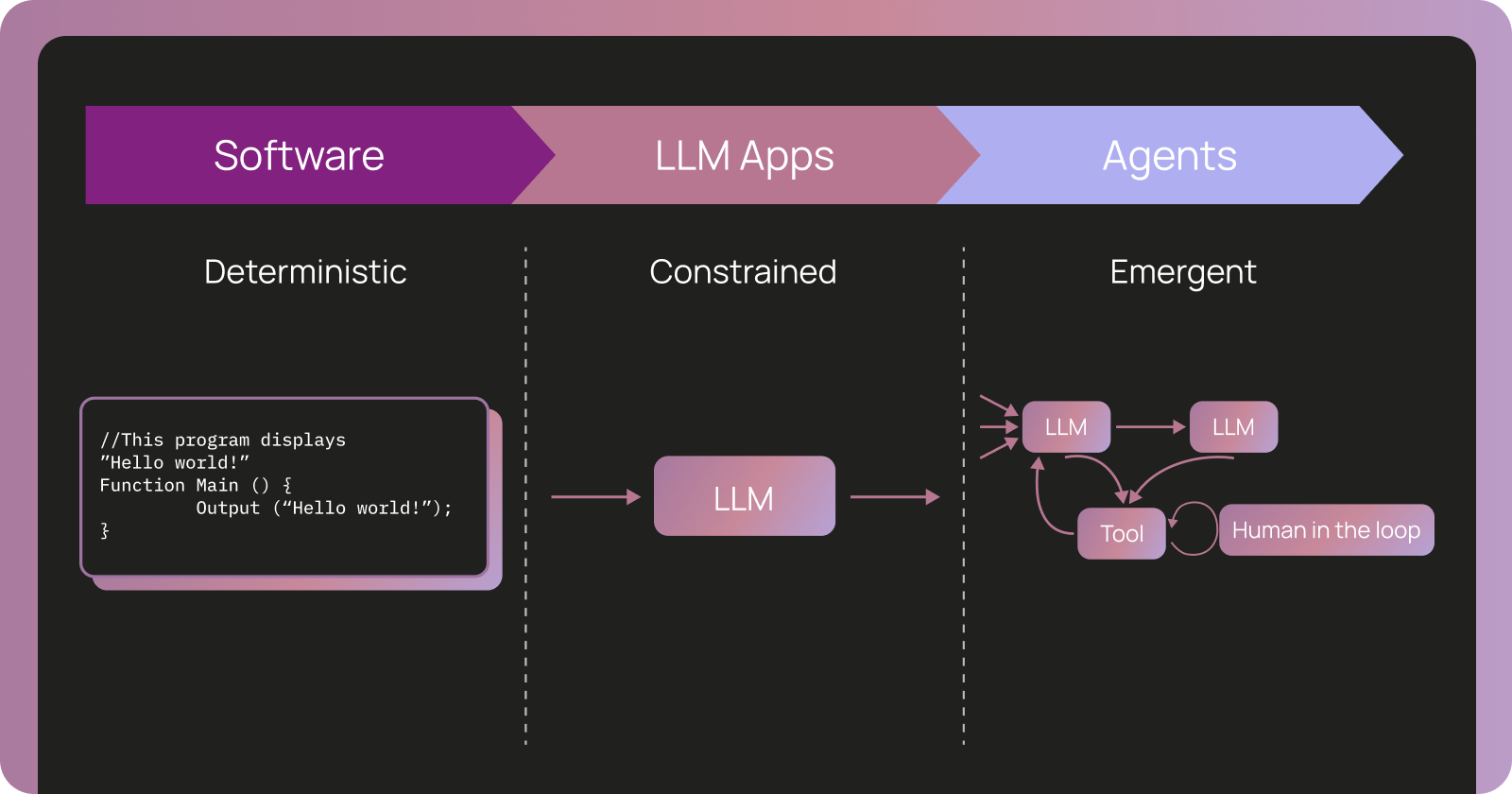
- •Agent behavior only emerges at runtime and is exclusively captured through observability traces, making production traces the foundation of evaluation strategy rather than separate testing artifacts[1][3]
- •Evaluation granularity maps directly to observability primitives: single-step evaluation for individual runs, full-turn evaluation for complete traces, and multi-turn evaluation for maintaining context across conversations[1]
- •Dual-layered evaluation approach combines offline evaluations using curated golden datasets to catch regressions and edge cases, with online evaluations running on real production traces in real-time to capture unpredictability[6]
- •Production traces power continuous validation through trajectory checks, efficiency monitoring, quality scoring via LLM-as-judge, and failure alerts that surface issues before user reports[1]
- •Leading observability platforms like LangSmith, W&B Weave, and Langfuse use OpenTelemetry standards with custom instrumentation to capture full reasoning traces including prompts, tool selection logic, and execution paths[2][4]
📊 Competitor Analysis▸ Show
| Platform | Primary Use Case | Key Features | Pricing Model | Best For |
|---|---|---|---|---|
| LangSmith | LangChain-centric agent debugging | Step-by-step inspection, run replay, side-by-side comparison, Insights Agent (GA Oct 2025) | $39/month per seat | LangChain/LangGraph teams with annotation queues |
| W&B Weave | Multi-framework observability | MCP auto-logging, guardrails, real-time behavior controls | Under CoreWeave (post-2025 acquisition) | Deep agent trace observability across frameworks |
| Langfuse | Multi-step pipeline monitoring | Real-time execution tracking, cost analysis, performance insights | Not specified | General LLM application performance monitoring |
| Truesight | Expert-grounded output evaluation | Domain-specific quality assessment | Not specified | Teams where domain experts define quality standards |
| Arize Phoenix | OTel-native self-hosting | OpenTelemetry-native architecture | Self-hosted option | Organizations requiring on-premise deployment |
| Comet Opik | Automated optimization | Automated improvement workflows | Not specified | Teams seeking continuous optimization |
| Braintrust | CI/CD integration | Pipeline integration, automated logging | Not specified | Teams with existing CI/CD workflows |
🛠️ Technical Deep Dive
• Observability Primitives Architecture: Traces, runs, and threads form the foundational data structures; traces capture complete execution paths including prompts, tool calls, and state changes; runs represent individual agent steps; threads maintain multi-turn conversation context[1] • Instrumentation Standards: OpenTelemetry (OTel) standard enables metadata sharing across frameworks; custom instrumentation layers provide framework-specific flexibility beyond standard telemetry[2] • Evaluation Metrics Layers: Three-layer evaluation framework operates on final output metrics, individual agent component assessment, and underlying LLM performance measurement[7] • Trajectory Analysis: LLM-as-judge methodology evaluates not just outputs but decision paths, tool-calling patterns, and guardrail compliance; trajectory checks flag unusual patterns and verify safety/policy guardrail ordering[1][6] • Production Trace Integration: Automatic CI/CD logging converts test suites into datasets; traces become queryable datasets enabling drill-down analysis to identify where agents diverge from ground truth[6] • Performance Benchmarking: Baseline establishment measures application performance without instrumentation; platform integration tests measure overhead introduction across five leading observability tools[2]
🔮 Future ImplicationsAI analysis grounded in cited sources
The convergence of observability and evaluation represents a fundamental paradigm shift in AI systems development. Unlike traditional software where testing and tracing are separate concerns, agentic systems require unified workflows where production traces directly inform evaluation strategies. This creates several industry implications: (1) Observability becomes a first-class requirement rather than optional monitoring, driving adoption of platforms like LangSmith and W&B Weave across enterprise teams; (2) The dual-layered evaluation approach (offline safety nets plus online production monitoring) establishes new quality standards for production-grade agents, particularly in regulated domains; (3) Real-time failure detection and trajectory analysis enable proactive issue resolution before user impact, reducing operational risk; (4) The standardization around OpenTelemetry and custom instrumentation creates ecosystem consolidation opportunities; (5) Human-in-the-loop mechanisms and annotation queues at scale suggest emerging roles for specialized evaluation engineering teams; (6) Domain-specific evaluation tools (like Truesight for expert-grounded assessment) indicate market segmentation by vertical requirements rather than generic solutions.
⏳ Timeline
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- langchain.com — Agent Observability Powers Agent Evaluation
- aimultiple.com — Agentic Monitoring
- blog.langchain.com — January 2026 Langchain Newsletter
- goodeyelabs.com — Top AI Agent Evaluation Tools 2026
- youtube.com — Watch
- blog.langchain.com — Customers Monday
- aws.amazon.com — Evaluating AI Agents Real World Lessons From Building Agentic Systems at Amazon
- braintrust.dev — Best AI Evaluation Tools 2026
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: LangChain Blog ↗