Nemotron-3-Super Dominates OpenClaw Benchmark
💡Learn how Nemotron-3-Super tops agent benchmarks via efficiency, not size
⚡ 30-Second TL;DR
What Changed
120B total parameters with 12.7B active per token
Why It Matters
Demonstrates efficient sparse models excel in agent benchmarks, potentially reducing compute costs for robotic AI applications. Signals shift toward consistency-focused evals in agent development.
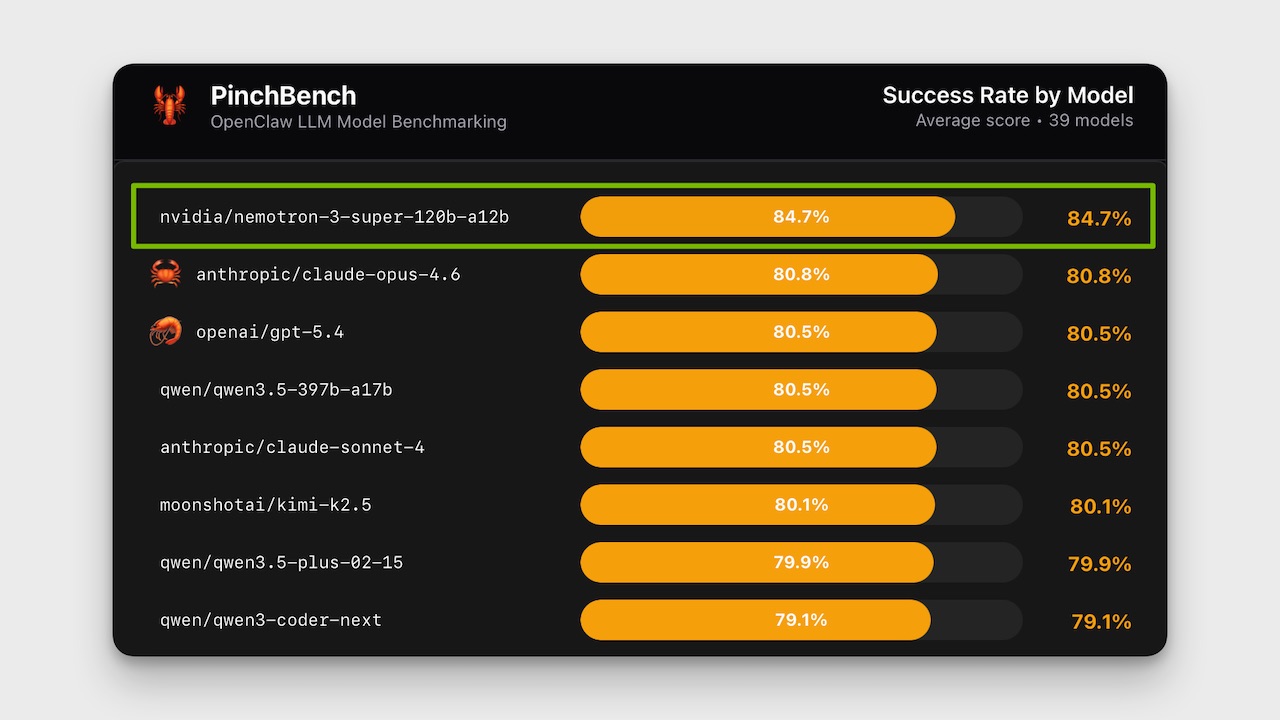
What To Do Next
Test Nemotron-3-Super on PinchBench to benchmark your OpenClaw agent's consistency.
🧠 Deep Insight
Web-grounded analysis with 9 cited sources.
🔑 Enhanced Key Takeaways
- •Nemotron-3-Super employs a hybrid Mamba-Transformer mixture-of-experts architecture, integrating Mamba layers for sequence efficiency and Transformer layers for precision reasoning[1][2][5].
- •The model was pre-trained on 25 trillion tokens, followed by post-training with supervised fine-tuning and reinforcement learning across 21 environments using NeMo Gym, involving over 1.2 million rollouts[1][5][7].
- •It achieves 2.2x higher inference throughput than GPT-OSS-120B and 7.5x higher than Qwen3.5-122B on specific sequence lengths, with 452 tokens per second output speed[2][7][8].
- •CrowdStrike reported 3x higher accuracy in production threat hunting compared to their prior model after early access testing[3].
📊 Competitor Analysis▸ Show
| Benchmark | Nemotron 3 Super | Qwen3.5-122B | GPT-OSS-120B |
|---|---|---|---|
| SWE-Bench Verified (OpenHands) | 60.47% | 66.40% | 41.90% |
| SWE-Bench Multilingual | 45.78% | — | 30.80% |
| Terminal Bench (hard) | 25.78% | 26.80% | 24.00% |
| Terminal Bench Core 2.0 | 31.00% | 37.50% | 18.70% |
| Throughput (vs baseline) | 2.2x / 7.5x | Baseline | Baseline |
🛠️ Technical Deep Dive
- •Hybrid MoE architecture combines Mamba-Transformer backbone for 4x improved memory and compute efficiency[2][5].
- •Multi-token prediction enables predicting multiple future words simultaneously, achieving 3x faster inference[4].
- •Native NVFP4 precision on NVIDIA Blackwell platform reduces memory requirements and delivers up to 4x faster inference than FP8 on Hopper, with no accuracy loss[4][5].
- •Supports 1M token context window, scoring 91.75% on RULER at 1M tokens[2][4].
- •Post-training via RL in NeMo Gym across 21 configurations with 1.2M+ rollouts for agent workflows[1][5].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (9)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- jonpeddie.com — Nvidia Nemotron 3 Super
- llm-stats.com — Nemotron 3 Super Launch
- thedeepview.com — Nvidia Boosts Open Models with Nemotron 3 Super
- blogs.nvidia.com — Nemotron 3 Super Agentic AI
- developer.nvidia.com — Introducing Nemotron 3 Super an Open Hybrid Mamba Transformer Moe for Agentic Reasoning
- digitalworlditalia.it — Nvidia Lancia Nemotron 3 Super Modello Open Da 120b Parametri Per Lai Agentica Enterprise 178401
- research.nvidia.com — Nvidia Nemotron 3 Super Technical Report
- artificialanalysis.ai — Nvidia Nemotron 3 Super 120b A12b
- ollama.com — Nemotron 3 Super
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: OpenClaw.report ↗