Nemotron 3 Nano Launches Serverless on Bedrock
💡Serverless Nemotron 3 Nano on Bedrock: instant access to NVIDIA LLM without infra hassle
⚡ 30-Second TL;DR
What Changed
Nemotron 3 Nano now fully managed and serverless on Amazon Bedrock
Why It Matters
Enables AI practitioners to access cutting-edge NVIDIA LLMs without managing infrastructure, speeding up prototyping and production deployment on AWS. Reduces costs and complexity for serverless inference at scale.
What To Do Next
Log into Amazon Bedrock console and invoke Nemotron 3 Nano for your next generative AI experiment.
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
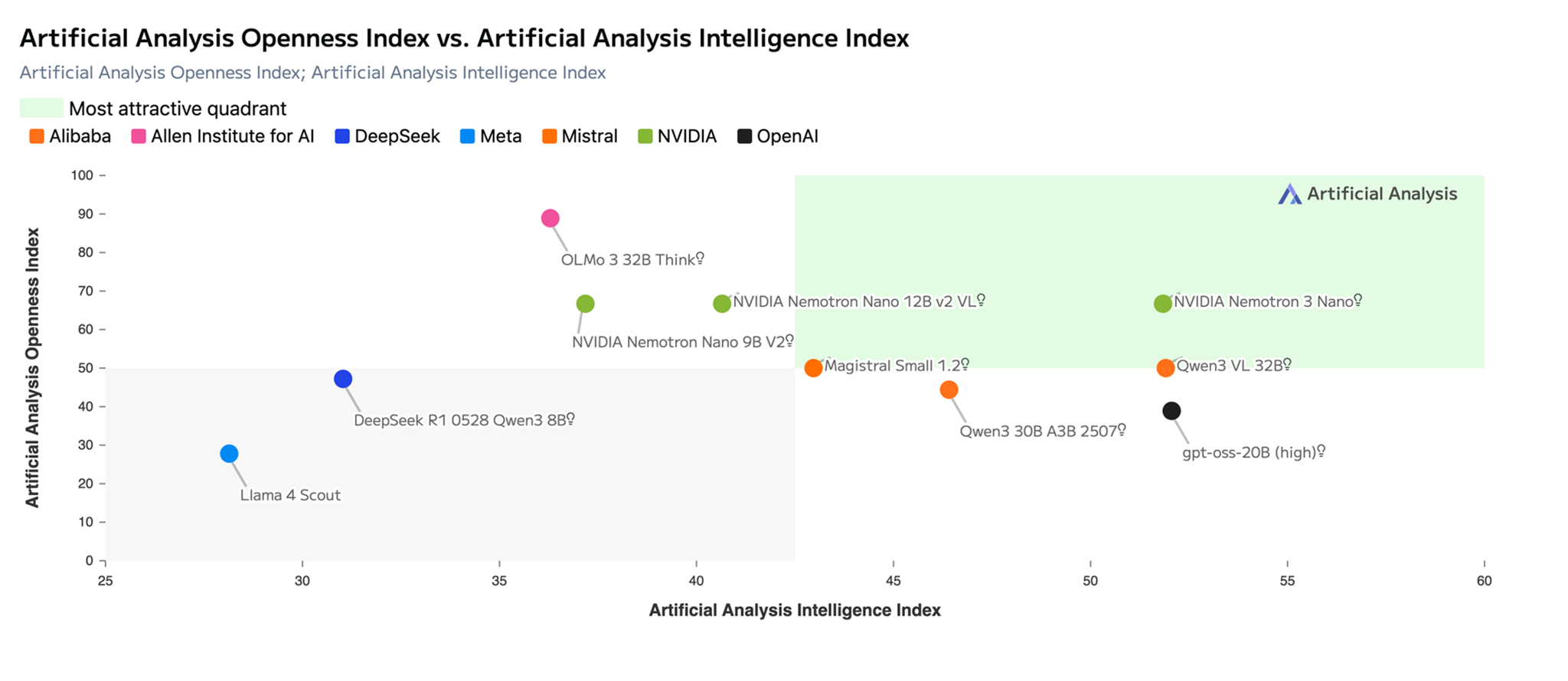
- •Nemotron 3 Nano features a 30B parameter hybrid Mixture-of-Experts (MoE) model activating up to 3B parameters, delivering 4x higher token throughput and up to 60% reduced reasoning-token generation compared to Nemotron 2 Nano[1][3][4].
- •The model supports a 1-million-token context window and native tool calling, powering Project Mantle inference engine on Bedrock for OpenAI API compatibility and multi-region availability including US East, US West, Asia Pacific, South America, and Europe[1][2][4].
- •Available as open-weights with datasets and recipes, Nemotron 3 Nano leads benchmarks like SWE Bench Verified, GPQA Diamond, AIME 2025, and LiveCodeBench for coding, math, and agentic tasks[3][5].
- •Also deployed on Amazon SageMaker JumpStart and supported on Google Cloud, CoreWeave, and other platforms beyond Bedrock[4][5].
🛠️ Technical Deep Dive
- •30B total parameters with 3B active parameters in hybrid MoE architecture combining Transformer and Mamba elements for efficiency[1][3][5].
- •1-million-token context window (262k on Bedrock), explicit reasoning controls via token budget, advanced RLHF and multi-environment post-training[1][3][4].
- •Optimized for agentic AI: 4x throughput vs. Nemotron 2 Nano, leads open <30B models on SWE Bench Verified, GPQA Diamond, AIME 2025, LiveCodeBench, IFBench[3][4][5].
- •Powered by Project Mantle for serverless inference with QoS controls, automated capacity, OpenAI API compatibility[1].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- aws.amazon.com — Nvidia Nemotron 3 Nano Amazon Bedrock
- aws.amazon.com — Nvidia Nemotron 3 Nano Amazon Bedrock
- engineering.com — Nvidia Introduces Open Nemotron 3 Models for Agentic AI
- nvidianews.nvidia.com — Nvidia Debuts Nemotron 3 Family of Open Models
- aihub.hkuspace.hku.hk — Nvidia Nemotron 3 Nano 30b Moe Model Is Now Available in Amazon Sagemaker Jumpstart
- pricepertoken.com — Nvidia Nemotron 3 Nano 30b A3b
- calculator.holori.com — Nvidia.nemotron Nano 3 30b
- eweek.com — Nvidia Nemotron 3 Nano Neuron
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗