🔥PyTorch Blog•Stalecollected in 20m
Meta Optimizes PyTorch Training for Rec/Rank Workloads
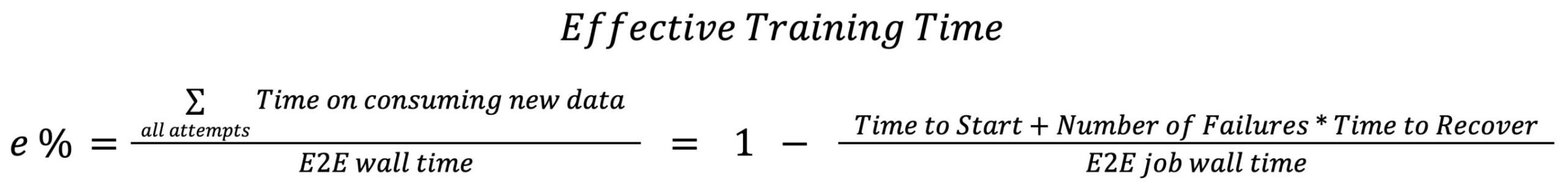
💡Meta's PyTorch tips to slash rec/rank training time under compute limits
⚡ 30-Second TL;DR
What Changed
Aggressive ROI targets under tight compute for large AI models
Why It Matters
Helps AI practitioners reduce training costs and improve efficiency for similar large-scale recsys workloads. Demonstrates real-world Meta engineering practices applicable to production environments.
What To Do Next
Read PyTorch Blog post and benchmark its optimizations on your recsys training jobs.
Who should care:Developers & AI Engineers
Key Points
- •Aggressive ROI targets under tight compute for large AI models
- •Scaling workloads complicate infrastructure effectiveness
- •Meta's PyTorch optimizations for rec/rank training pipelines
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Meta implemented 'TorchRec' as a specialized library within the PyTorch ecosystem to address the unique challenges of large-scale embedding tables and sparse feature processing inherent in recommendation systems.
- •The optimizations leverage 'Fused Embedding' kernels and 'Sharded Data Parallelism' to reduce communication overhead and memory fragmentation during distributed training across thousands of GPUs.
- •Meta's approach utilizes 'Dynamic Batching' and 'Pipeline Parallelism' to maximize GPU utilization rates, specifically targeting the bottleneck of high-latency data retrieval from massive, multi-terabyte embedding tables.
📊 Competitor Analysis▸ Show
| Feature | Meta (TorchRec/PyTorch) | NVIDIA (HugeCTR) | Google (TensorFlow Recommenders) |
|---|---|---|---|
| Primary Framework | PyTorch | Custom/NVIDIA-optimized | TensorFlow |
| Hardware Focus | GPU-agnostic (optimized for H100/B200) | NVIDIA-exclusive | TPU/GPU |
| Embedding Strategy | Sharded Data Parallelism | Model Parallelism (HugeCTR) | Embedding Columns |
| Deployment | High (Internal Meta scale) | High (NVIDIA stack) | High (Google Cloud/Ads) |
🛠️ Technical Deep Dive
- Sharded Embedding Tables: Implementation of distributed embedding tables that partition parameters across multiple GPU devices to bypass single-node memory limits.
- Fused Kernels: Utilization of custom CUDA kernels to combine embedding lookup, pooling, and gradient accumulation into single operations, minimizing kernel launch overhead.
- Communication Overlap: Use of asynchronous collective communication (NCCL) to overlap the communication of sparse gradients with the computation of dense layers.
- Quantization: Integration of INT8 and FP8 quantization techniques for embedding tables to reduce memory footprint and increase throughput without significant accuracy degradation.
🔮 Future ImplicationsAI analysis grounded in cited sources
Meta will transition its primary recommendation training stack to native FP8 support.
The current focus on memory-bound optimization suggests a move toward lower-precision formats to further increase embedding table capacity per GPU.
PyTorch will integrate more automated sharding heuristics for recommendation models.
Reducing the manual effort required to configure complex sharding strategies is the next logical step for scaling these workloads to larger teams.
⏳ Timeline
2022-03
Meta open-sources TorchRec, a PyTorch domain library for recommendation systems.
2023-09
Meta introduces FSDP (Fully Sharded Data Parallel) enhancements for large-scale model training.
2025-02
Meta announces integration of advanced kernel fusion techniques for sparse operations in PyTorch.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗