Meta Open-Sources RCCLX for AMD GPUs
💡Meta's open-source RCCLX boosts AMD GPU comms for AI training, rivaling Nvidia tools
⚡ 30-Second TL;DR
What Changed
Open-sourcing initial RCCLX version
Why It Matters
Enables efficient multi-GPU training on AMD hardware, reducing Nvidia dependency for AI practitioners. Broadens access to high-performance computing for research and development.
What To Do Next
Clone the RCCLX repo from Meta Engineering and integrate it with your Torchcomms setup on AMD GPUs.
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
- •RCCLX integrates CTran transport library from NVIDIA platforms to AMD, enabling GPU-resident AllToAllvDynamic collective[1].
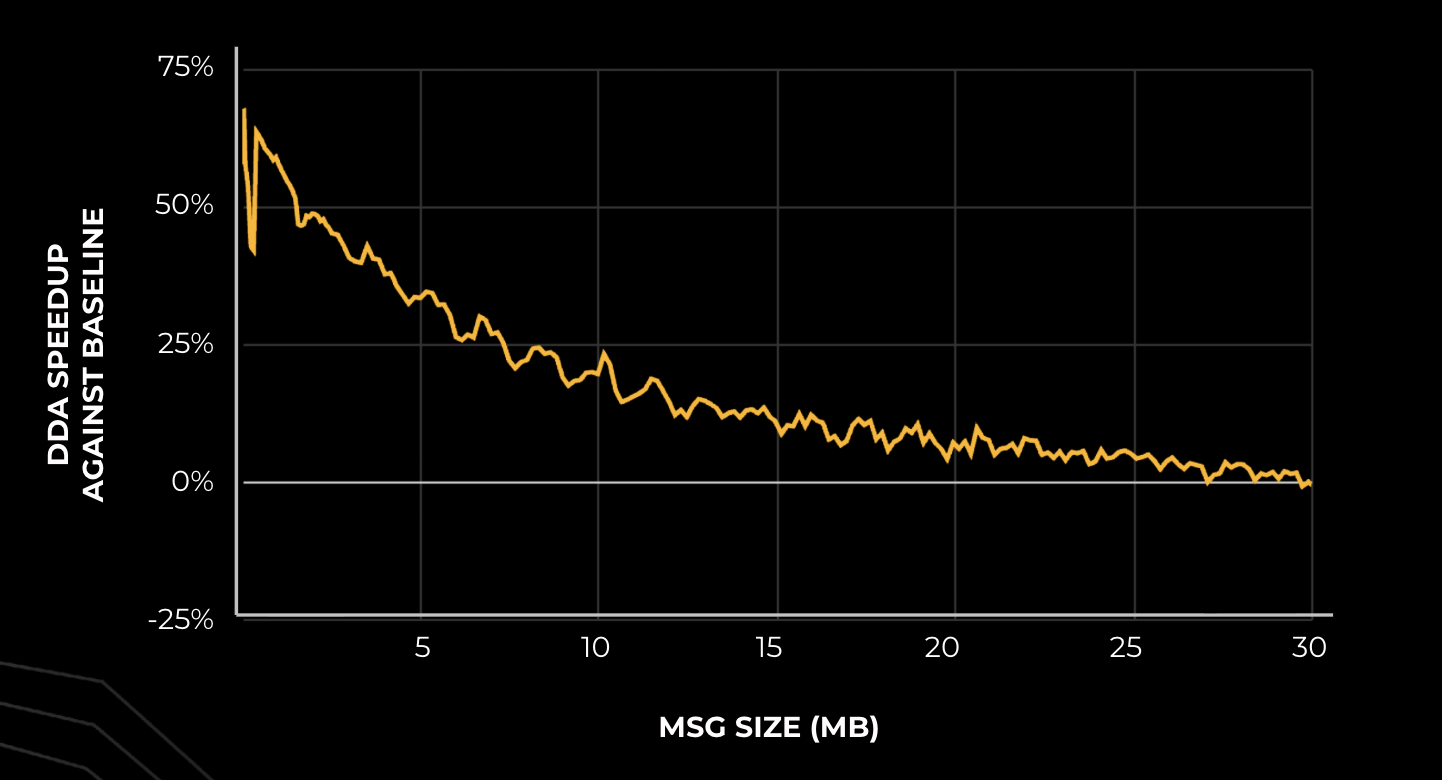
- •Introduces DDA (Dynamic Data Augmentation?) outperforming RCCL baseline by 10-50% on decode and 10-30% on prefill with AMD MI300X GPUs, reducing TTIT by ~10%[1].
- •Employs parallel P2P mesh communication leveraging AMD Infinity Fabric, with LP collectives in FP32/BF16 tuned for single-node, using minimal quantization for stability[1].
- •AMD's ROCm 7.2 enhances RCCL with topology-aware communication, GDA support via rocSHMEM for low-latency GPU-direct async intra/inter-node[3].
🛠️ Technical Deep Dive
- •DDA achieves 10-50% speedup over RCCL baseline for small message decode and 10-30% for prefill on MI300X, via parallel P2P mesh on Infinity Fabric with FP32 compute for stability[1].
- •LP collectives dynamically enable low-precision optimizations with 1-2 quantizations per collective, supporting FP8 range; tuned for single-node FP32/BF16[1].
- •CTran integration brings AllToAllvDynamic as GPU-resident collective; full features planned in future months[1].
- •ROCm complements with GPUDirect Async (GDA) in rocSHMEM for CPU-bypassing GPU P2P and RDMA via RNIC[3].
- •RCCL in ROCm 7.2 offers MI350 optimizations, higher XGMI throughput, single-node perf gains[6].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- engineering.fb.com — Rrcclx Innovating GPU Communications Amd Platforms Meta
- opensourceforu.com — Amd Goes Open Source with Rocm to Challenge Nvidia Cuda
- rocm.blogs.amd.com — Readme
- rocm.docs.amd.com — Release Notes
- techbuzz.ai — Meta Drops 6gw Amd GPU Deal Breaks Nvidia Stranglehold
- GitHub — Releases
- rocm.blogs.amd.com — Readme
- technewsworld.com — Assessing Amds 2025 Momentum and Its Ces 2026 Reveals 180068
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Meta Engineering Blog ↗