🛠️Meta Engineering Blog•Freshcollected in 30m
Meta Maps Tribal Knowledge with AI in Pipelines
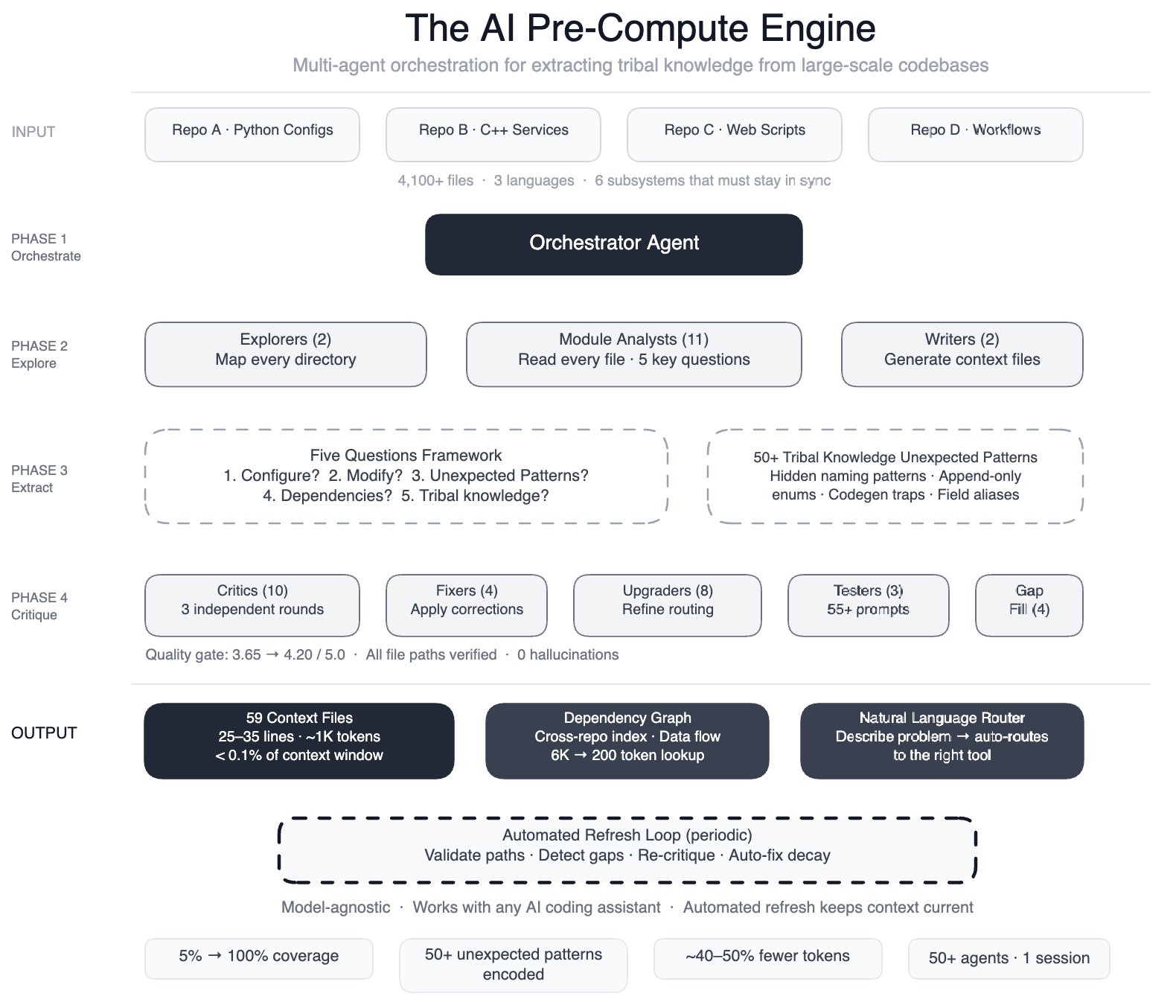
💡Meta's fix for AI coding on 4k+ file pipelines boosts agent speed—key for large codebases.
⚡ 30-Second TL;DR
What Changed
Targeted AI agents at Meta's data pipelines: 4 repos, 3 languages, 4,100+ files.
Why It Matters
This technique helps AI practitioners apply AI to massive, multi-repo codebases, accelerating development workflows and reducing tribal knowledge silos.
What To Do Next
Read Meta Engineering Blog to implement tribal knowledge mapping for your AI coding agents.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The system utilizes a graph-based representation of codebase dependencies to explicitly link 'tribal knowledge'—often found in documentation, code comments, and commit history—to specific pipeline logic.
- •Meta implemented a retrieval-augmented generation (RAG) architecture that prioritizes context from cross-repository dependency chains, reducing the 'hallucination' rate of AI agents when modifying legacy pipeline code.
- •The initiative is part of Meta's broader 'AI-Native Engineering' strategy, aiming to reduce the onboarding time for new engineers working on complex data infrastructure by automating the discovery of undocumented system constraints.
🛠️ Technical Deep Dive
- •Architecture: Employs a Knowledge Graph (KG) to map relationships between code entities, configuration files, and human-authored documentation.
- •Context Retrieval: Uses a hybrid search approach combining vector embeddings for semantic similarity and graph traversal for structural dependency mapping.
- •Agentic Workflow: Implements a multi-step 'plan-and-verify' loop where the agent proposes changes, validates them against a simulated pipeline environment, and iterates based on feedback from the KG.
- •Data Integration: Ingests metadata from internal CI/CD logs, Slack discussions, and Wiki pages to dynamically update the tribal knowledge graph.
🔮 Future ImplicationsAI analysis grounded in cited sources
Meta will transition to fully autonomous maintenance of its core data pipelines by 2027.
The success of mapping tribal knowledge reduces the human-in-the-loop requirement for routine pipeline refactoring and dependency updates.
The 'tribal knowledge' mapping framework will be open-sourced as part of the PyTorch or Meta Open Source ecosystem.
Meta has a consistent history of open-sourcing internal developer productivity tools to establish industry standards for AI-assisted software engineering.
⏳ Timeline
2024-09
Meta initiates internal audit of AI coding assistant performance on legacy data infrastructure.
2025-03
Meta Engineering releases initial prototype of the graph-based context retrieval system.
2026-01
Full-scale deployment of the tribal knowledge mapping system across the four primary data pipeline repositories.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: Meta Engineering Blog ↗