LLM-Driven Feature Discovery: A Black-Box Approach to Interpretability
💡Learn a simple, unsupervised way to audit proprietary LLM behaviors without needing access to internal model weights.
⚡ 30-Second TL;DR
What Changed
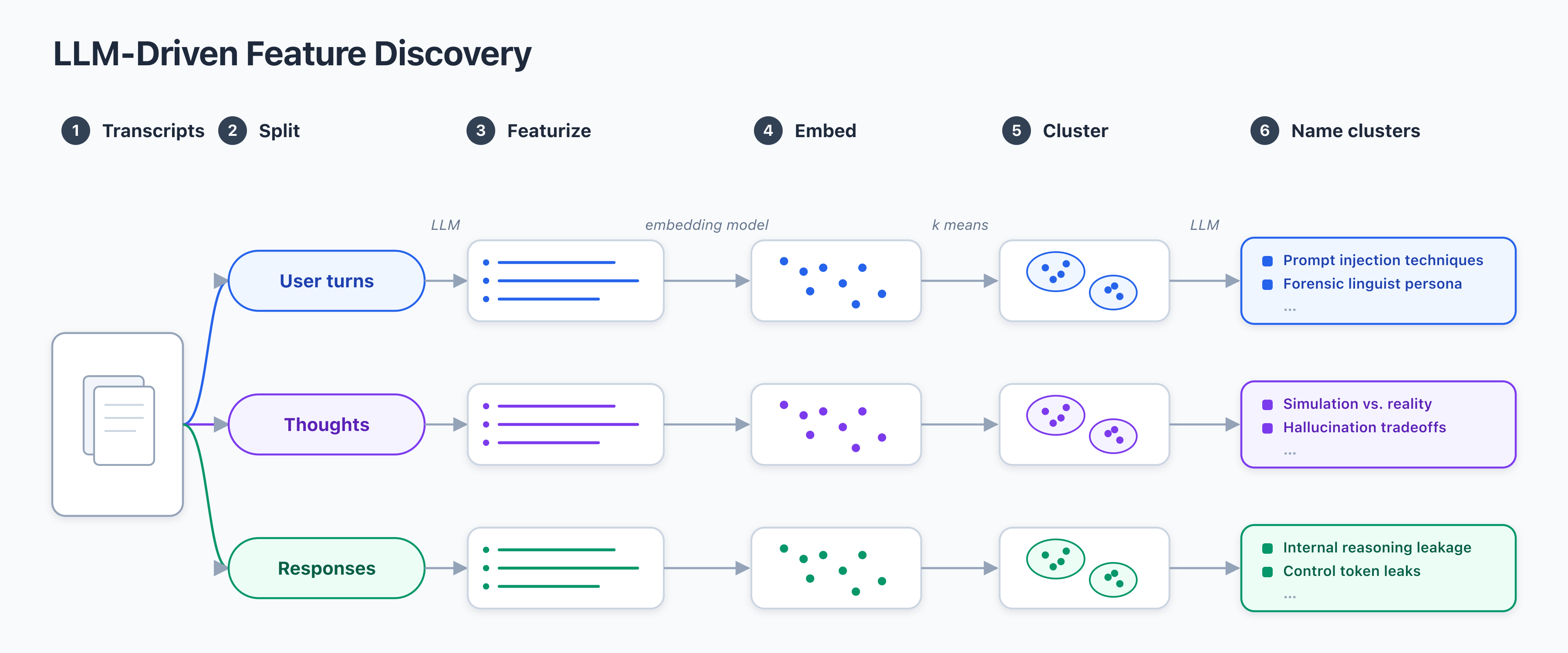
Uses a black-box LLM to generate and cluster semantic features from user, thought, and assistant transcript segments.
Why It Matters
This method lowers the barrier for researchers to perform behavioral analysis on proprietary models where internal activations are inaccessible. It provides a scalable way to audit model outputs for safety and alignment.
What To Do Next
Apply this clustering pipeline to your own model's chat logs to identify recurring, undocumented behaviors without needing internal model access.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The methodology leverages 'LLM-as-a-judge' paradigms to perform automated interpretability, reducing the human-in-the-loop requirement for labeling latent behaviors.
- •Unlike Sparse Autoencoders (SAEs) which operate on activation vectors, this approach relies on the semantic density of output tokens, making it model-agnostic across different architectures.
- •The technique addresses the 'superposition' problem in black-box settings by using clustering algorithms to disentangle overlapping semantic concepts within high-dimensional text embeddings.
- •Initial validation studies indicate that this method can detect 'sycophancy' and 'refusal' patterns in chat models with higher recall than keyword-based filtering.
- •The approach is specifically optimized for large-scale dataset analysis, where the cost of running full-model activation extraction (SAE training) is computationally prohibitive.
📊 Competitor Analysis▸ Show
| Feature | Black-Box Feature Discovery | Sparse Autoencoders (SAEs) | Mechanistic Interpretability (Circuit Analysis) |
|---|---|---|---|
| Access Required | Black-Box (API/Output) | White-Box (Activations) | White-Box (Weights/Activations) |
| Computational Cost | Low (Inference only) | High (Training/Storage) | Very High (Manual/Expert) |
| Granularity | Semantic/Behavioral | Neuronal/Feature-level | Circuit/Logic-level |
| Interpretability | High (Natural Language) | Medium (Requires labeling) | Low (Requires expertise) |
🛠️ Technical Deep Dive
- Implementation utilizes a two-stage pipeline: (1) Semantic extraction via a high-capacity LLM to generate feature descriptors, and (2) Embedding-based clustering (e.g., HDBSCAN or K-Means) on the resulting feature vectors.
- The system treats the LLM as a feature extractor by prompting it to identify 'latent intents' or 'behavioral markers' within a sliding window of the chat transcript.
- Dimensionality reduction (typically UMAP or PCA) is applied to the extracted semantic embeddings before clustering to mitigate the curse of dimensionality.
- The 'black-box' nature is maintained by strictly utilizing the input-output mapping of the target model, bypassing the need for logit or hidden state access.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AI Alignment Forum ↗