☁️AWS Machine Learning Blog•Stalecollected in 30m
Lambda for Effective Nova Reward Functions
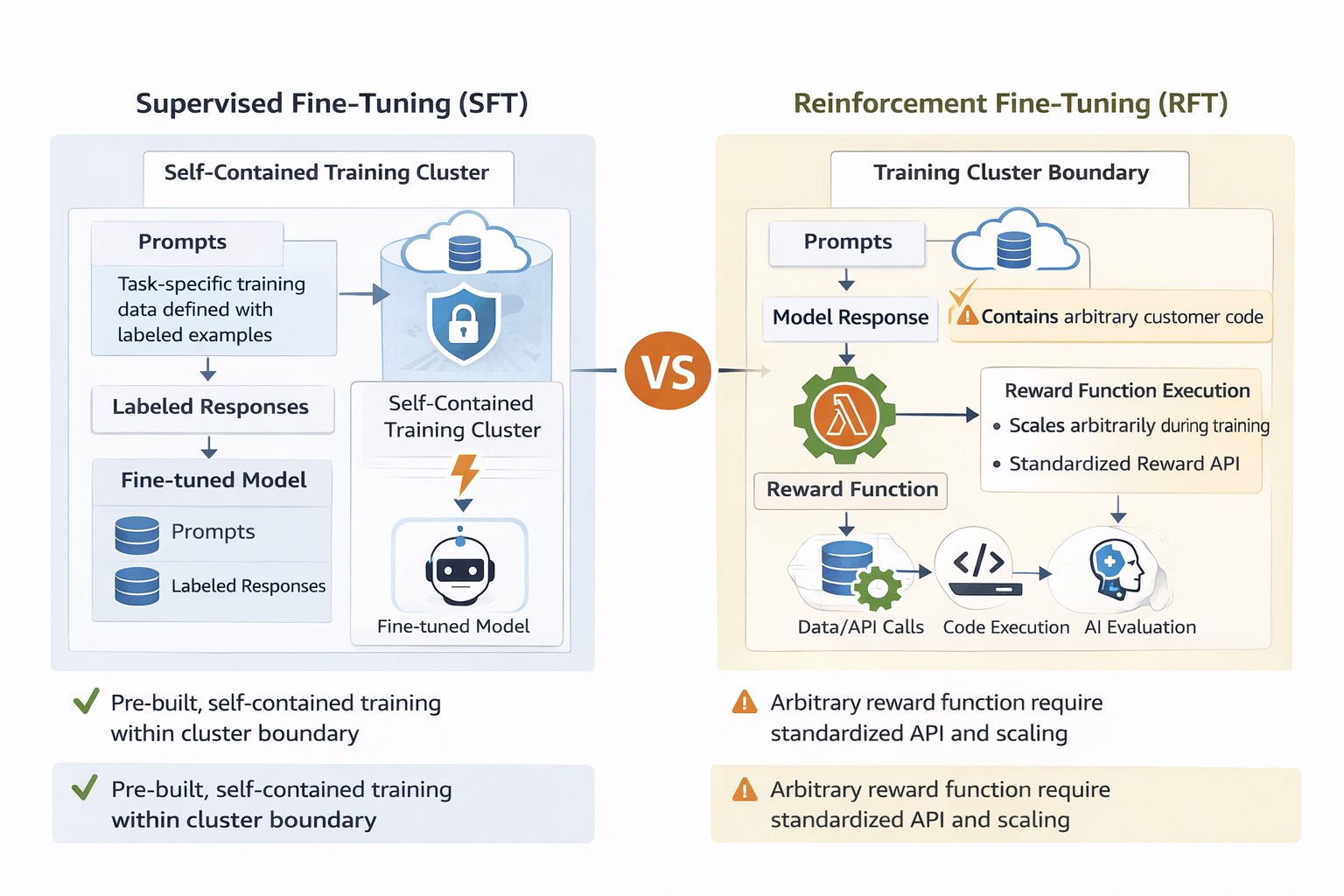
💡Scalable Lambda rewards for Nova: prevent hacking, cut costs—code included!
⚡ 30-Second TL;DR
What Changed
Choose RLVR for objectively verifiable tasks, RLAIF for subjective evaluation
Why It Matters
Empowers AI practitioners to customize Nova models scalably on AWS, reducing costs and mitigating reward hacking risks for better fine-tuning outcomes.
What To Do Next
Deploy the sample Lambda reward function code to experiment with Nova customization.
Who should care:Developers & AI Engineers
Key Points
- •Choose RLVR for objectively verifiable tasks, RLAIF for subjective evaluation
- •Design multi-dimensional reward systems to prevent reward hacking
- •Optimize Lambda functions for training scale and monitor with CloudWatch
- •Includes working code examples and deployment guidance
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •AWS Lambda integration leverages the 'Provisioned Concurrency' feature to mitigate cold-start latency, which is critical for maintaining high throughput during the iterative feedback loops of Reinforcement Learning (RL) training.
- •The architecture utilizes Amazon EventBridge to orchestrate the asynchronous invocation of Lambda functions, decoupling the reward computation from the primary model training pipeline to ensure fault tolerance.
- •Implementation patterns emphasize the use of AWS X-Ray for distributed tracing, allowing developers to identify bottlenecks in reward function execution time that could otherwise throttle the overall training velocity.
📊 Competitor Analysis▸ Show
| Feature | AWS Nova + Lambda | Google Vertex AI (RLHF/RLAIF) | Azure OpenAI Service (Fine-tuning) |
|---|---|---|---|
| Reward Customization | High (Serverless/Code-based) | Managed (Vertex AI Pipelines) | Limited (Managed Fine-tuning) |
| Compute Model | Pay-per-invocation (Lambda) | Managed Infrastructure | Managed Infrastructure |
| Integration | Deep AWS Ecosystem | Deep Google Cloud Ecosystem | Deep Azure/OpenAI Ecosystem |
🛠️ Technical Deep Dive
- Reward Function Architecture: Lambda functions act as stateless compute nodes that ingest model outputs via Amazon SQS queues, returning scalar reward values to the training orchestrator.
- RLVR Implementation: Verifiable tasks utilize deterministic logic (e.g., regex, code execution environments) within the Lambda runtime to ensure 100% accuracy in reward assignment.
- RLAIF Implementation: Subjective tasks leverage a secondary 'judge' model (typically a smaller, faster Nova variant) invoked via Lambda to score outputs based on alignment criteria.
- Scalability: The system supports auto-scaling of Lambda concurrency limits to match the parallelization factor of the distributed training job, preventing queue saturation.
🔮 Future ImplicationsAI analysis grounded in cited sources
Serverless reward functions will become the industry standard for enterprise model alignment.
The decoupling of compute-intensive reward logic from training infrastructure significantly reduces operational overhead and cost for custom model tuning.
Real-time monitoring of reward function latency will become a primary KPI for AI engineering teams.
As training datasets grow, the efficiency of the reward pipeline directly dictates the time-to-convergence for RL-based model customization.
⏳ Timeline
2024-12
AWS announces the Amazon Nova foundation model family.
2025-05
AWS introduces enhanced model customization features for Amazon Nova.
2026-02
AWS expands serverless integration support for high-performance machine learning workflows.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗