Helion Accelerates Autotuning with Bayesian Optimization
💡Speeds up ML kernel autotuning 10x+ for PyTorch devs building high-perf code.
⚡ 30-Second TL;DR
What Changed
Helion DSL enables PyTorch-like syntax for high-performance ML kernels
Why It Matters
This enhancement reduces time spent on manual tuning, allowing AI practitioners to focus on kernel design. It improves efficiency in developing optimized ML code for production.
What To Do Next
Install Helion and test Bayesian Optimization on your ML kernel autotuning workflow.
🧠 Deep Insight
Web-grounded analysis with 9 cited sources.
🔑 Enhanced Key Takeaways
- •Helion compiles to automatically tuned Triton code, automating tensor indexing, memory management, and hardware-specific optimizations like PID swizzling and loop reordering.[1][5]
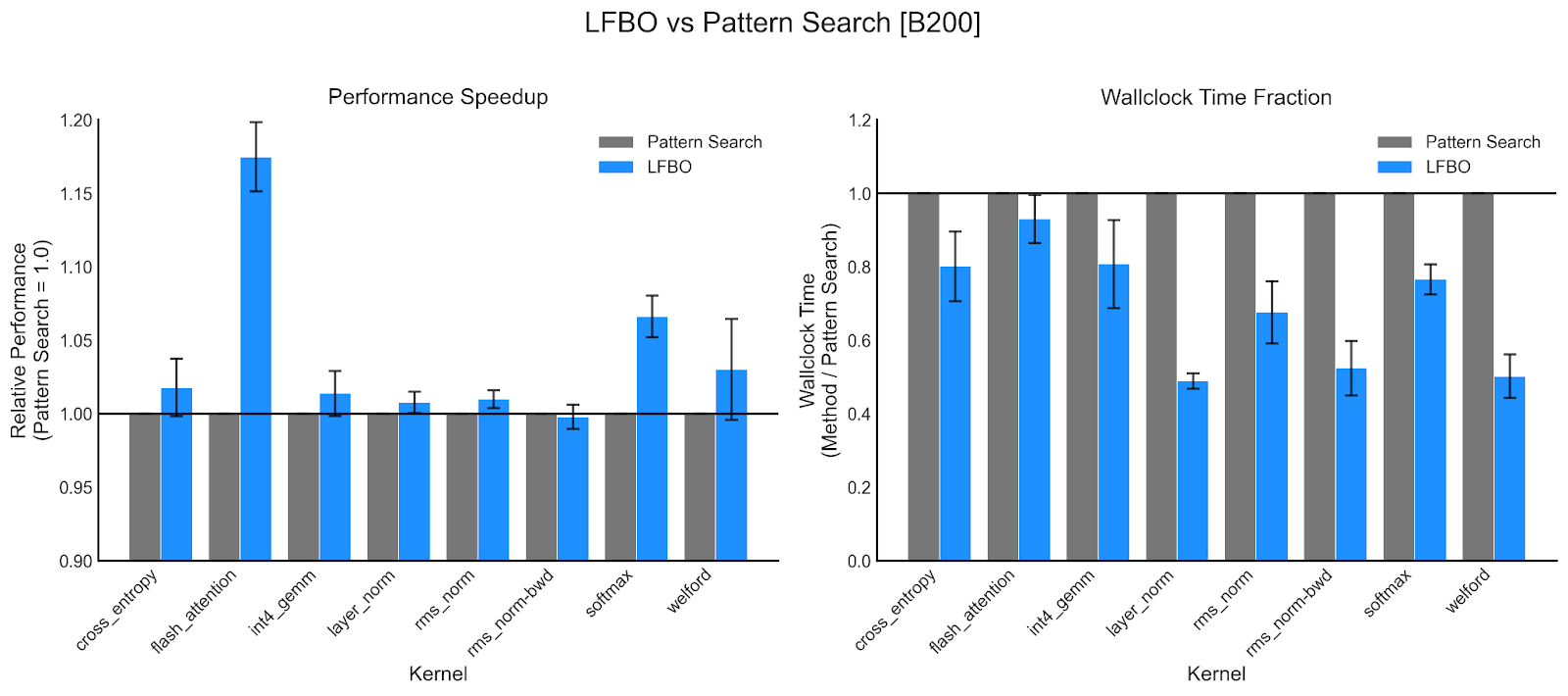
- •Autotuning in Helion evaluates hundreds of Triton configurations from one kernel, taking around 10 minutes and completing searches like 1520 configs in 586 seconds for better performance portability.[1][5]
- •Helion supports advanced features such as kernel templating via Python closures, L2 grouping with subtiling for cache improvements, and integration with PyTorch 2 including tensor subclasses.[4][5]
🛠️ Technical Deep Dive
- •Helion uses hl.tile to subdivide iteration space into tiles, autotuning tile sizes, iteration order, memory layouts, and flattening options, mapping to thousands of Triton configs.[1]
- •Autotuning occurs late in the pipeline during code generation, allowing single-run parsing and IR transformation before exploring configs efficiently.[1]
- •Configurable parameters include num_warps (number of warps) and num_stages (pipeline stages passed to Triton), enabling diverse output code variations.[5]
- •Supports automated optimizations: tensor indexing (strides, pointers, TensorDescriptors), implicit masking, grid sizes/PID mappings, looping reductions, warp specialization, and unrolling.[5]
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (9)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗