⚖️AI Alignment Forum•Stalecollected in 3h
Hard CoT Interp Tasks Released
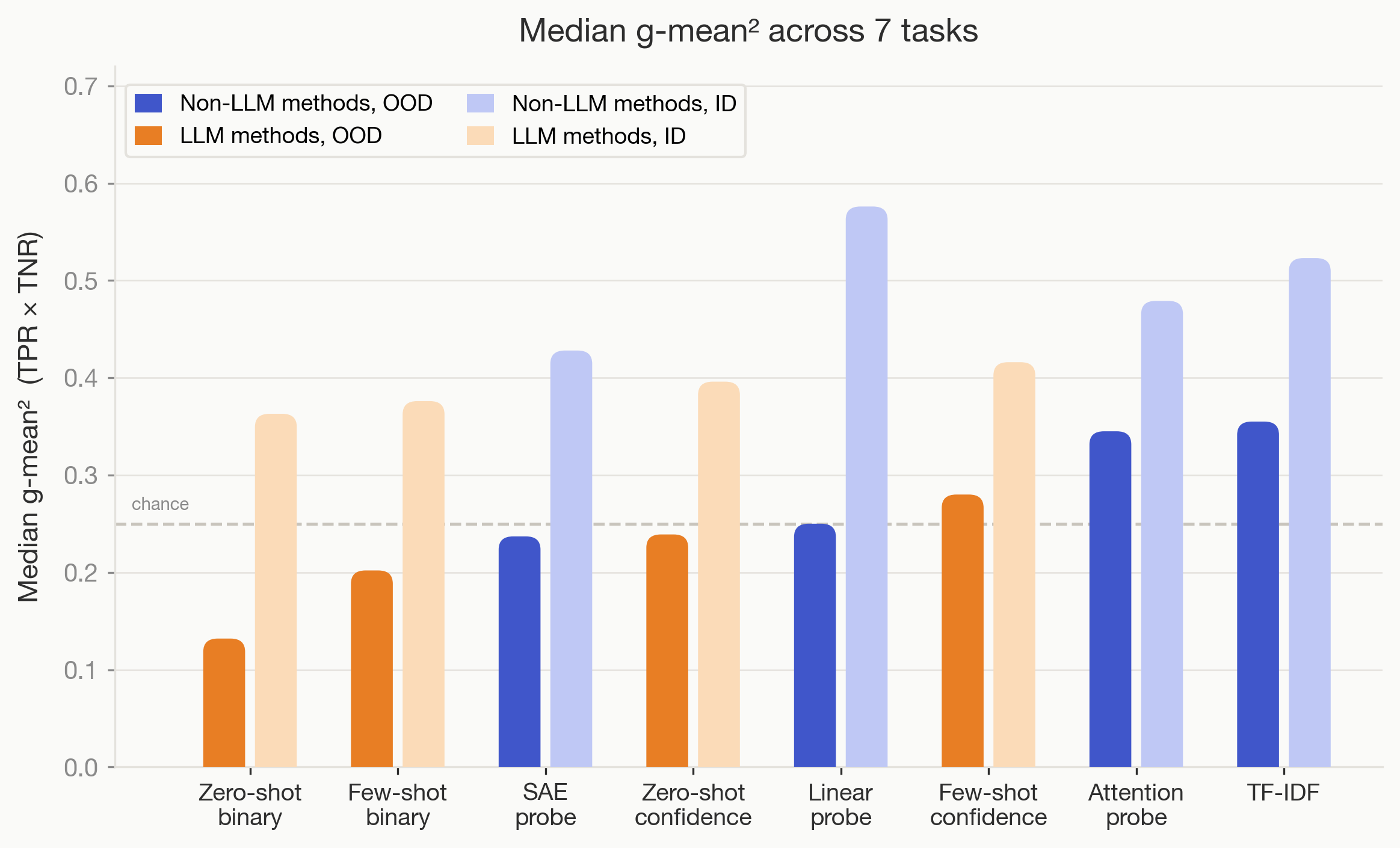
💡9 OOD-hard CoT tasks: probes beat LLMs—benchmark your interp tools!
⚡ 30-Second TL;DR
What Changed
9 tasks for CoT interp: predict stopping, sycophancy, confidence, etc.
Why It Matters
Provides standardized OOD benchmark for CoT tools, vital for AI safety techniques. Highlights probes/TF-IDF as strong baselines, spurring non-LLM method development.
What To Do Next
Download datasets from the AI Alignment Forum repo and baseline your CoT interp method on the 7 main OOD tasks.
Who should care:Researchers & Academics
Key Points
- •9 tasks for CoT interp: predict stopping, sycophancy, confidence, etc.
- •Open-sourced datasets/code with in-dist/OOD splits.
- •Baselines: TF-IDF/attention probes beat zero/few-shot LLM monitors OOD.
- •7 main + 2 misc tasks to prove OOD robustness.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The research highlights a significant 'interpretability gap' where LLM-based monitors suffer from catastrophic performance degradation when faced with out-of-distribution (OOD) reasoning patterns, suggesting that current model-based evaluation techniques are brittle.
- •The testbed specifically targets the 'black-box' nature of CoT by focusing on latent state analysis, moving away from relying solely on the final output tokens to infer the model's internal reasoning process.
- •By demonstrating that simpler, non-LLM methods like TF-IDF and linear probes outperform complex LLM monitors on OOD tasks, the study challenges the prevailing industry trend of using larger models to supervise smaller ones for safety and alignment.
🛠️ Technical Deep Dive
- •The dataset includes nine distinct tasks categorized into core reasoning and auxiliary behavioral checks, such as detecting sycophancy (agreement with user bias) and confidence calibration.
- •The evaluation framework utilizes a split-dataset approach, explicitly separating in-distribution (ID) training data from OOD test sets to measure generalization capability in reasoning interpretability.
- •Baseline implementations include sparse linear probes trained on hidden state activations and TF-IDF vectorizers applied to CoT reasoning traces, providing a low-compute benchmark for comparison against LLM-based monitoring agents.
- •The testbed is designed to be model-agnostic, allowing researchers to plug in various transformer-based architectures to test the robustness of their internal representation mapping.
🔮 Future ImplicationsAI analysis grounded in cited sources
LLM-based monitoring will become a secondary evaluation strategy.
The demonstrated failure of LLM monitors on OOD data suggests that robust interpretability will require more stable, non-generative statistical methods.
Interpretability benchmarks will shift toward OOD robustness.
The release of this testbed sets a new standard for evaluating interpretability tools based on their ability to handle reasoning patterns not seen during training.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AI Alignment Forum ↗