Fine-tune Nemotron ASR on EC2
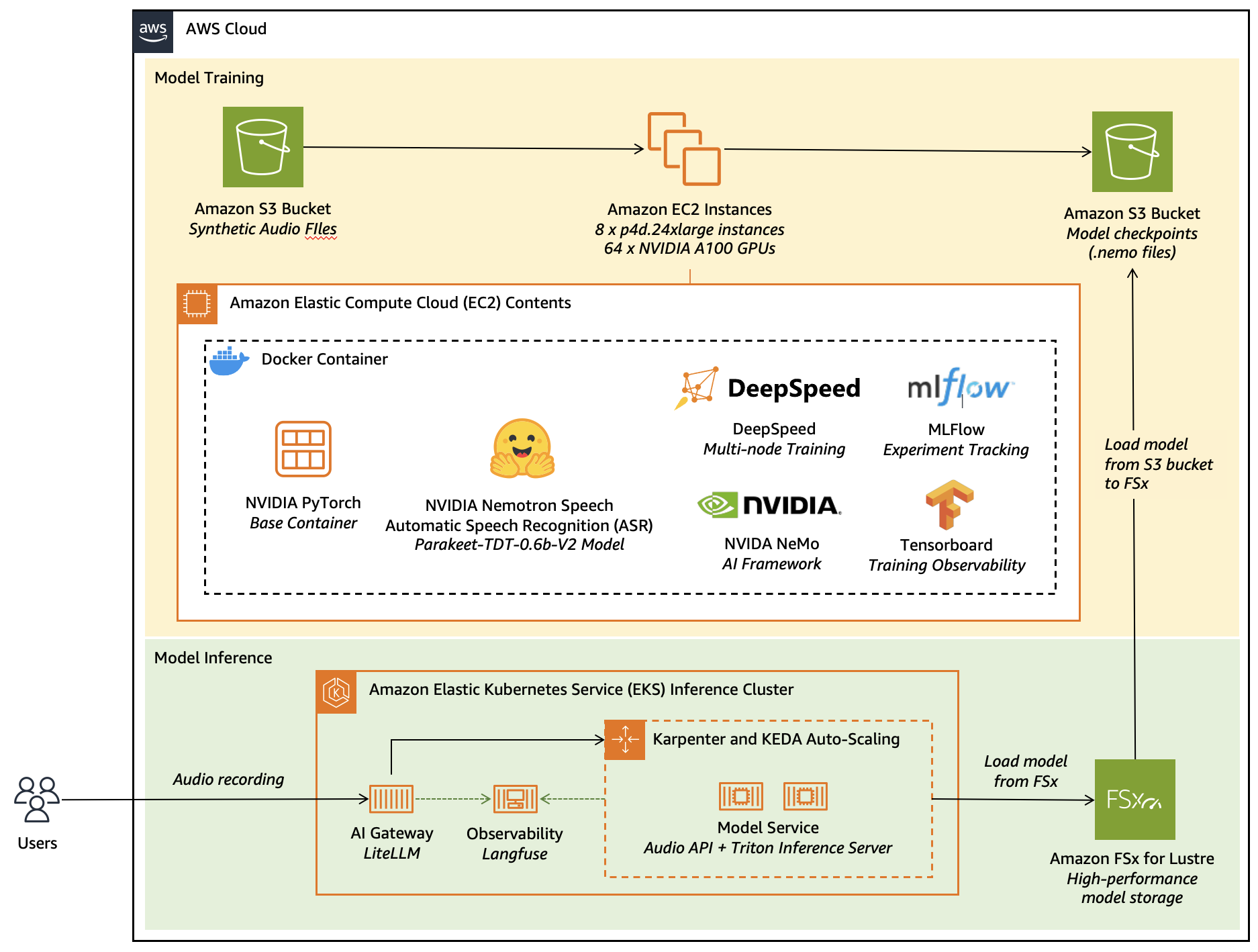
💡Top ASR model fine-tuned on EC2 with synthetic data—perfect for custom speech domains!
⚡ 30-Second TL;DR
What Changed
Fine-tune Parakeet TDT 0.6B V2 ASR model
Why It Matters
Achieves superior transcription accuracy for niche domains like medical or legal speech. Lowers barrier for custom ASR deployment on cloud. Boosts specialized AI apps with top-performing open models.
What To Do Next
Spin up EC2 GPU instance and run the Nemotron fine-tuning script from the AWS blog.
🧠 Deep Insight
Web-grounded analysis with 8 cited sources.
🔑 Enhanced Key Takeaways
- •Parakeet-TDT-0.6B-V2 uses a FastConformer-TDT architecture with Token-and-Duration Transducer (TDT) decoder, enabling efficient single-pass transcription of up to 24-minute audio segments[1][4][6].
- •Model achieves top benchmark performance including 6.05% WER on clean LibriSpeech test-clean, RTF of 3380-3386 (transcribing ~56 min audio/sec at batch 128), and #1 ranking on Hugging Face Open ASR Leaderboard as of May 2025[1][3][5].
- •Supports multilingual transcription with average WER of 11.97% on Fleurs, 7.83% on MLS, robust noise handling (e.g., 8.39% WER at SNR 5), auto-punctuation/casing, word-level timestamps, and CC-BY-4.0 commercial license[1][2][3].
- •Available as deployable NIM microservice on NVIDIA platforms and AWS Marketplace for SageMaker inference with 16kHz mono audio input[4][6].
📊 Competitor Analysis▸ Show
| Feature | Parakeet-TDT-0.6B-V2 | OpenAI Whisper Medium/Large V3 |
|---|---|---|
| Parameters | 600M | 769M / 1.55B |
| WER (LibriSpeech clean) | 2.5% / 6.05% avg | 3.6% / higher |
| RTF (batch 128) | 3380-3386 (~56 min/sec) | Lower throughput |
| Word-level timestamps | Yes | No (segment-level) |
| Noise robustness | Strong (8.39% WER SNR 5) | Good |
| Pricing | Free (CC-BY-4.0), AWS Marketplace | API-based (paid) |
🛠️ Technical Deep Dive
- •Architecture: FastConformer encoder + TDT (Token-and-Duration Transducer) decoder; 600M parameters; trained with full attention for long audio (up to 24 min/chunk)[1][4][6].
- •Input: 16kHz mono WAV/FLAC or raw audio/base64 JSON; supports HTTP/gRPC inference on SageMaker; optional word timestamps via enable_word_time_offsets flag[2][4].
- •Performance: LibriSpeech clean 6.05% WER, RTF 3380 (batch 128); multilingual (e.g., en 4.85% Fleurs, de 5.04%); noise robust (SNR 5: 8.39% WER); CUDA-accelerated, offline capable[1][2][3][5].
- •Features: Auto punctuation/capitalization, superior number/technical term accuracy, song lyrics handling; NeMo framework for fine-tuning/adaptation[3][6][7].
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (8)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- qed42.com — Nvidia Parakeet Tdt 0 6b V2 a Deep Dive Into State of the Art Speech Recognition Architecture
- build.nvidia.com — Modelcard
- towardsai.net — %ef%b8%8f Building a Local Speech to Text System with Parakeet Tdt 0 6b V2
- aws.amazon.com — Prodview R2hrzimxjtjfg
- modal.com — Open Source Stt
- docs.nvidia.com — Asr
- drivendata.co — Child Asr Word Benchmark
- community.groq.com — 373
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗