🔥PyTorch Blog•Freshcollected in 40m
Faster Diffusion on Blackwell with MXFP8 & NVFP4
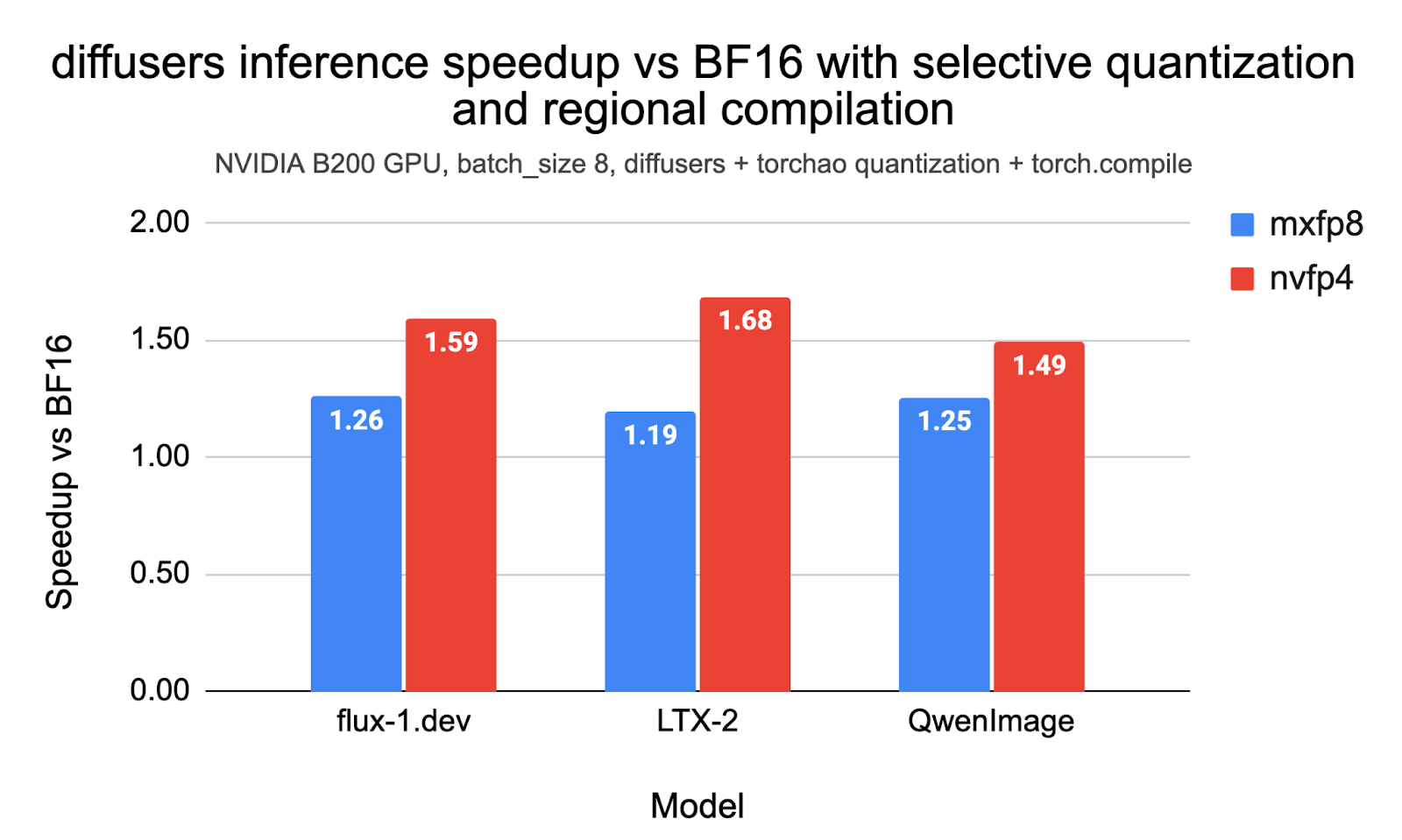
💡Speed up diffusion models 2-3x on Blackwell GPUs via PyTorch's MXFP8/NVFP4 support.
⚡ 30-Second TL;DR
What Changed
MXFP8 and NVFP4 formats accelerate diffusion on Blackwell GPUs
Why It Matters
This feature significantly reduces resource demands for diffusion models, enabling larger-scale training and faster inference on next-gen NVIDIA hardware. AI practitioners can now deploy realistic generative models more efficiently, accelerating innovation in visual media.
What To Do Next
Install PyTorch nightly and enable MXFP8 in Diffusers for Blackwell GPUs.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The integration leverages the Blackwell architecture's Transformer Engine, which natively supports micro-scaling formats like MXFP8 to reduce precision without significant loss in model fidelity.
- •TorchAO (PyTorch Architecture Optimization) provides the necessary quantization kernels to map these low-precision formats to the underlying hardware, effectively bypassing traditional FP16/BF16 memory bandwidth bottlenecks.
- •These optimizations specifically target the U-Net and Transformer-based denoising backbones common in Stable Diffusion 3 and Flux models, enabling higher batch sizes on single-GPU configurations.
🛠️ Technical Deep Dive
- •MXFP8 (Micro-scaling Formats): Utilizes a shared exponent across a vector of values to maintain dynamic range while reducing mantissa bits, optimized for Blackwell's tensor cores.
- •NVFP4: A proprietary 4-bit floating-point format designed for inference-heavy workloads, offering higher throughput than FP8 at the cost of reduced precision, managed via TorchAO's quantization API.
- •Memory Footprint: By switching from BF16 to MXFP8/NVFP4, the weight storage requirement is reduced by 2x to 4x, allowing larger models to fit entirely within the GPU's high-bandwidth memory (HBM3e).
- •Kernel Fusion: TorchAO implements fused quantization-dequantization kernels that minimize global memory access during the forward pass of the diffusion model's transformer blocks.
🔮 Future ImplicationsAI analysis grounded in cited sources
Real-time 4K video generation will become feasible on single-node consumer-grade Blackwell workstations.
The combination of 4-bit quantization and Blackwell's increased memory bandwidth significantly lowers the latency per denoising step required for high-resolution video synthesis.
Standardization of MXFP8 will lead to a decline in the use of FP16 for production-grade diffusion inference.
The performance-to-accuracy ratio provided by MXFP8 is superior to FP16, incentivizing developers to prioritize hardware-native low-precision formats for cost-efficient scaling.
⏳ Timeline
2024-03
NVIDIA announces the Blackwell GPU architecture with support for new micro-scaling formats.
2024-06
PyTorch introduces TorchAO (Architecture Optimization) library to simplify quantization and model optimization.
2025-02
NVIDIA releases initial software stack support for MXFP8 in the TensorRT-LLM and PyTorch ecosystem.
2026-04
PyTorch Blog announces specific optimizations for diffusion models using MXFP8 and NVFP4 on Blackwell.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗