💰钛媒体•Stalecollected in 27m
DeepSeek $10B Valuation; TSMC AI Crunch; China-US LLM Parity

💡DeepSeek $10B+ valuation, Nvidia quantum AI open-source, US-China LLM parity
⚡ 30-Second TL;DR
What Changed
DeepSeek first external funding talks, valuation >$10B
Why It Matters
Signals massive AI investments, infrastructure bottlenecks, and rapid China catch-up, reshaping global AI landscape and compute costs.
What To Do Next
Test HappyHorse-1.0 on LMSYS Arena and explore Nvidia ISING repo for quantum experiments.
Who should care:Founders & Product Leaders
Key Points
- •DeepSeek first external funding talks, valuation >$10B
- •TSMC unable to meet surging AI chip demand despite expansion
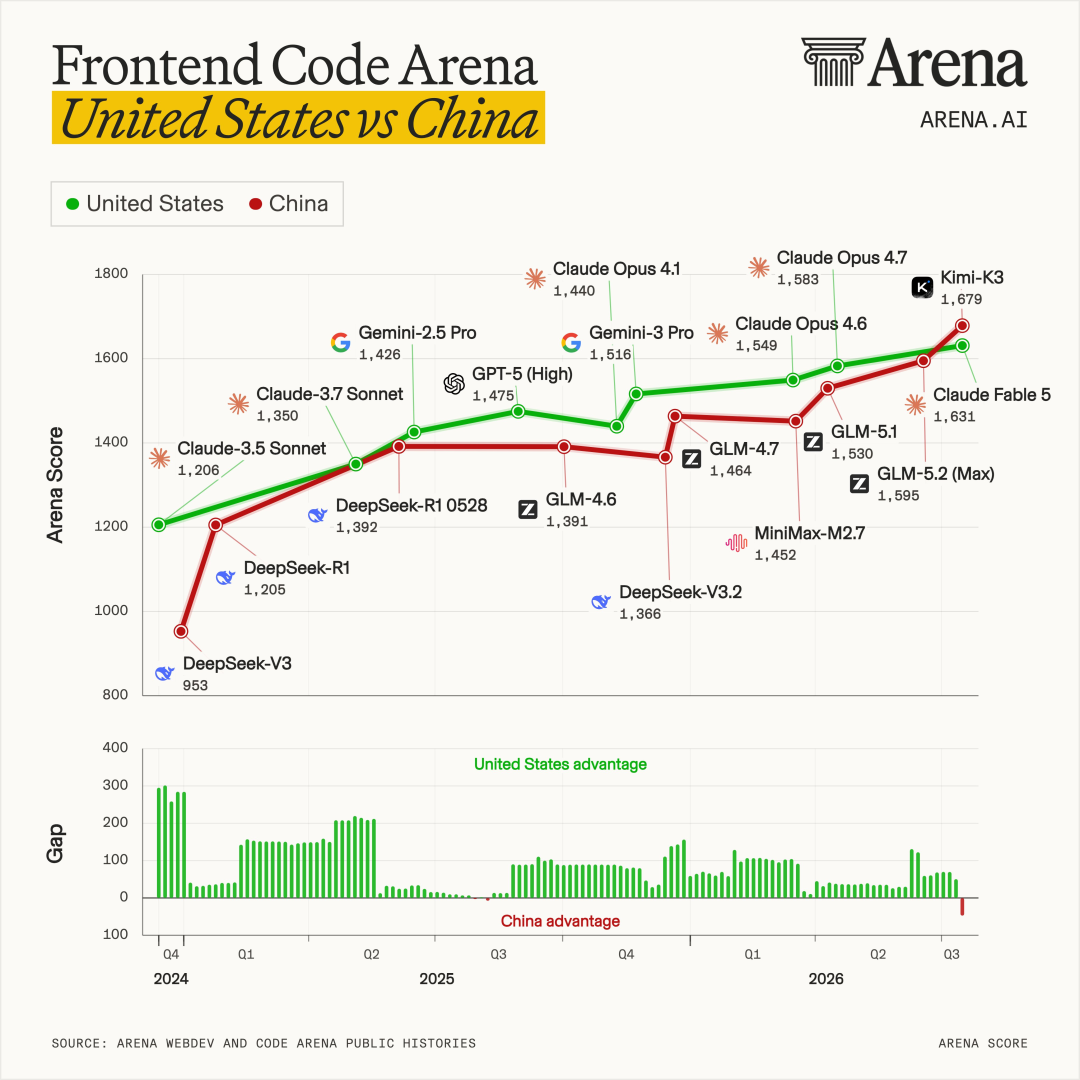
- •Stanford: US-China top LLM performance gap eliminated
- •HappyHorse-1.0 launches on LMSYS Arena, full release soon
- •Nvidia releases first open-source quantum AI model ISING
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •DeepSeek's valuation surge is driven by its proprietary 'DeepSeek-V3' architecture, which utilizes a Mixture-of-Experts (MoE) approach to achieve high performance with significantly lower training and inference costs compared to dense models.
- •The Stanford report highlighting US-China parity specifically points to the rapid adoption of open-weights architectures in China, which bypasses some of the hardware restrictions imposed by US export controls.
- •Nvidia's ISING model represents a shift toward 'Quantum-Inspired' AI, utilizing classical neural network architectures to simulate quantum mechanical systems, specifically targeting material science and drug discovery applications.
📊 Competitor Analysis▸ Show
| Feature | DeepSeek-V3 | GPT-4o | Claude 3.5 Opus |
|---|---|---|---|
| Architecture | MoE (Mixture-of-Experts) | Dense/Hybrid | Dense/Hybrid |
| Training Efficiency | High (Optimized for cost) | Moderate | Moderate |
| Primary Advantage | Cost-to-performance ratio | Ecosystem integration | Reasoning capabilities |
🛠️ Technical Deep Dive
- DeepSeek-V3 Architecture: Employs a Multi-head Latent Attention (MLA) mechanism to compress KV cache, significantly reducing memory bandwidth requirements during inference.
- ISING Model Specs: A transformer-based architecture trained on Hamiltonian datasets, utilizing a custom loss function designed to minimize energy states in simulated quantum systems.
- HappyHorse-1.0: A multimodal model utilizing a novel 'Token-Compression' layer that allows for 2x faster context window processing compared to standard attention mechanisms.
🔮 Future ImplicationsAI analysis grounded in cited sources
DeepSeek will likely pursue a public listing on the HKEX within 18 months.
The $10B valuation and move to external funding suggest a transition toward institutional transparency and liquidity requirements.
TSMC will implement tiered pricing for AI-specific nodes by Q4 2026.
Persistent supply-demand imbalances in advanced packaging (CoWoS) necessitate price discovery mechanisms to prioritize high-margin AI customers.
⏳ Timeline
2023-04
DeepSeek releases initial research papers on efficient MoE training.
2024-01
DeepSeek-V2 launch, marking the first major shift toward low-cost inference.
2025-02
DeepSeek-V3 architecture debut, achieving parity with frontier models on standard benchmarks.
2026-03
DeepSeek initiates Series A funding discussions with international venture capital firms.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: 钛媒体 ↗