📋TestingCatalog•Freshcollected in 24m
Condense launches proxy to cut AI coding agent bills
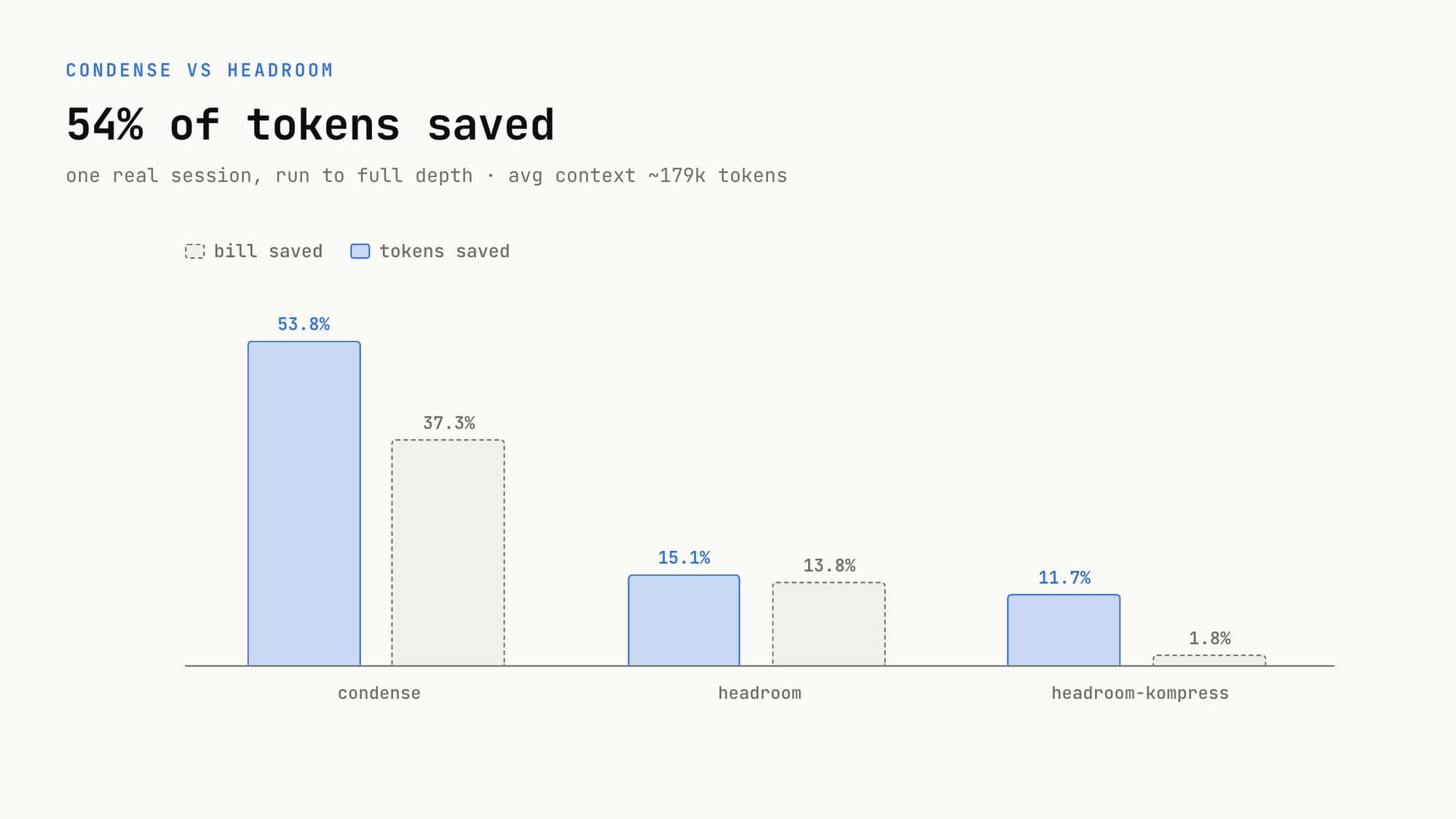
💡Cut your AI coding agent token bills by up to 72% with this new context-compression proxy.
⚡ 30-Second TL;DR
What Changed
Proxy service compresses context for AI coding agents
Why It Matters
This tool addresses the high cost of long-context AI coding, making complex agentic workflows more economically viable for developers and enterprises.
What To Do Next
Integrate the Condense.chat proxy into your existing coding agent pipeline to benchmark token savings on your most complex repositories.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Condense's proxy architecture functions as a middleware layer that intercepts API calls between the IDE/coding agent and the LLM provider, such as OpenAI or Anthropic.
- •The service specifically targets the 'context window bloat' issue common in long-running coding sessions where redundant file imports and boilerplate code consume excessive tokens.
- •Beyond cost reduction, the company claims the compression process improves agent performance by reducing the 'needle in a haystack' noise, allowing models to focus on relevant code snippets.
- •The proprietary models utilized are fine-tuned specifically for source code syntax and dependency graph analysis, ensuring that semantic meaning is preserved during the compression phase.
- •The proxy supports integration with popular AI coding assistants like Cursor, Windsurf, and VS Code extensions via simple environment variable configuration.
📊 Competitor Analysis▸ Show
| Feature | Condense.chat | Context-Caching Solutions (e.g., Anthropic/Gemini) | Traditional Proxy/Gateway |
|---|---|---|---|
| Primary Mechanism | Proprietary Compression Models | Native API Context Caching | Token Counting/Filtering |
| Cost Impact | Up to 72% reduction | Varies (Cache write/read fees) | Minimal (Management fees) |
| Model Agnostic | Yes | No (Provider specific) | Yes |
| Latency | Low (Optimized inference) | Very Low (Native) | Low |
🛠️ Technical Deep Dive
- The proxy utilizes a two-stage pipeline: a structural analyzer that maps the project's dependency graph and a semantic compressor that prunes non-essential code blocks.
- It employs a custom tokenization strategy that prioritizes function signatures, class definitions, and recent edit history over static library imports.
- The system maintains a stateful cache of the codebase, allowing it to perform incremental updates rather than re-processing the entire context window on every request.
- The architecture is designed to be stateless regarding the user's actual code, ensuring that the proxy does not store sensitive source code on its servers beyond the duration of the request processing.
🔮 Future ImplicationsAI analysis grounded in cited sources
AI coding agents will shift toward 'context-aware' middleware as a standard architectural pattern.
As token costs remain a barrier for enterprise-scale AI development, third-party optimization layers will become essential for cost-efficient agentic workflows.
LLM providers will likely integrate native compression features to compete with proxy services.
If third-party proxies successfully capture significant market share by reducing token consumption, major model providers will be incentivized to offer built-in, optimized context management to retain revenue.
⏳ Timeline
2026-03
Condense.chat enters private beta for enterprise coding teams.
2026-06
Public release of the Condense proxy service for AI coding agents.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: TestingCatalog ↗