Building Privacy-Aware Infrastructure for the AI-Native Era
💡Learn how Meta automates data privacy and governance to handle complex asset classification in AI-native systems.
⚡ 30-Second TL;DR
What Changed
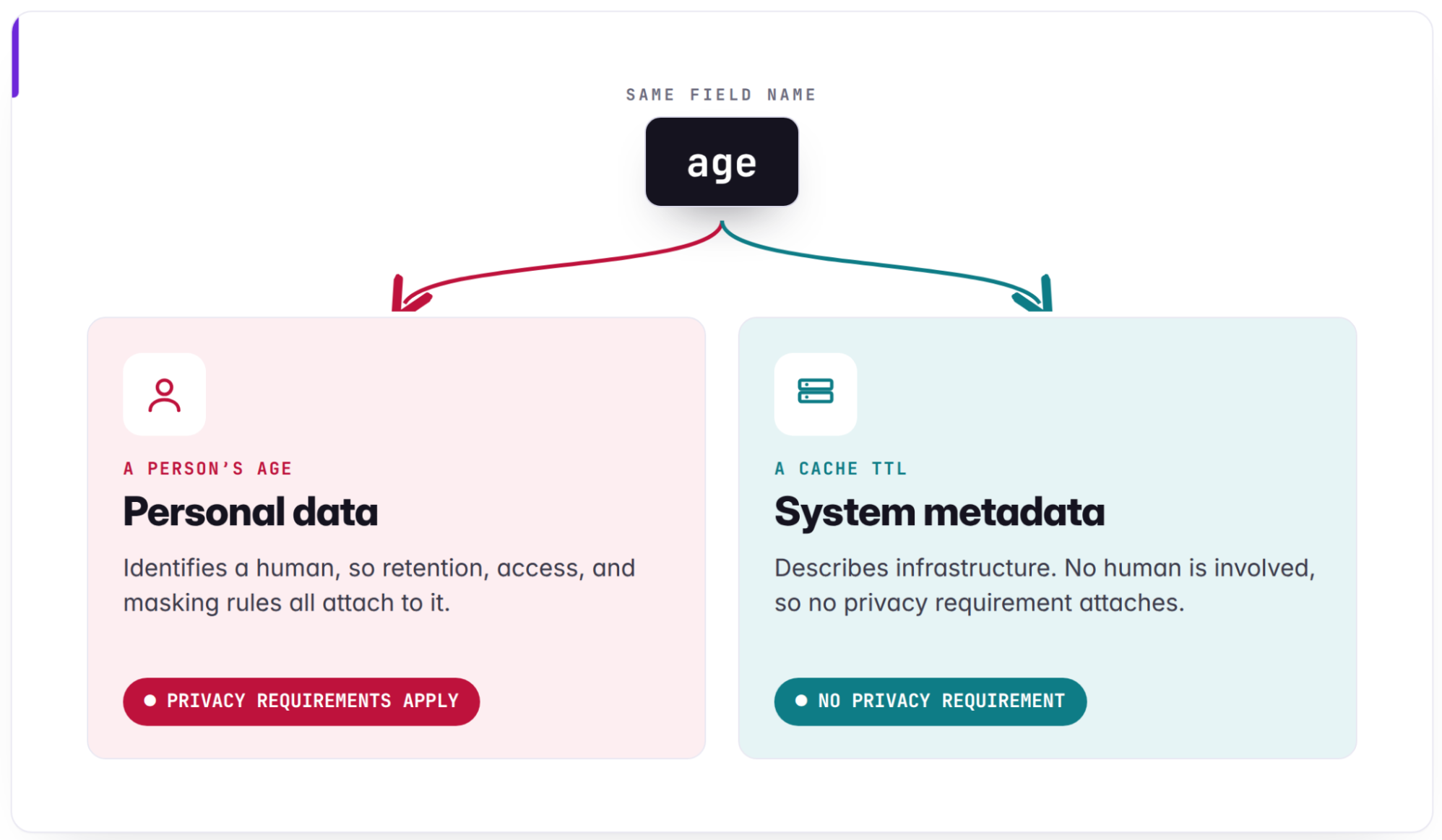
Privacy controls require deep, reliable understanding of data assets to function effectively.
Why It Matters
This research provides a framework for enterprises to manage data governance at scale, reducing the risk of privacy leaks in AI training pipelines. It highlights the necessity of metadata-driven infrastructure for AI-native compliance.
What To Do Next
Audit your data pipeline to identify ambiguous fields and implement a metadata tagging system before scaling your AI training datasets.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Meta utilizes a proprietary metadata-driven framework called 'Data Map' to maintain a real-time inventory of data lineage and sensitivity across its distributed AI training clusters.
- •The infrastructure integrates with Meta's 'Privacy-Preserving AI' (PPAI) initiative, which employs differential privacy techniques to ensure that individual user data points cannot be reconstructed from model weights.
- •Meta has implemented automated 'Data Lifecycle Management' (DLM) agents that trigger immediate deletion or anonymization protocols when a data asset's classification changes due to regulatory updates or policy shifts.
- •The system leverages Large Language Models (LLMs) internally to perform semantic analysis on unstructured data, improving the accuracy of classification for fields that lack standardized schemas.
- •Meta's approach incorporates 'Privacy-by-Design' auditing tools that simulate data access patterns to identify potential policy violations before AI models are deployed to production environments.
📊 Competitor Analysis▸ Show
| Feature | Meta (Privacy-Aware Infra) | Google (Cloud DLP/Vertex AI) | Microsoft (Purview/Azure AI) |
|---|---|---|---|
| Classification Engine | Proprietary Semantic/LLM-based | Cloud DLP / Sensitive Data Protection | Purview Information Protection |
| Privacy Technique | Differential Privacy / PPAI | Differential Privacy / K-Anonymity | Confidential Computing / Enclaves |
| Primary Focus | Social Graph / User Data | Enterprise Data / Cloud Services | Enterprise Compliance / Governance |
🛠️ Technical Deep Dive
- Data Map Architecture: Utilizes a graph-based database to map relationships between raw data ingestion points and downstream AI model training pipelines.
- Semantic Classification: Employs transformer-based models to classify unstructured data by analyzing context, reducing reliance on manual tagging.
- Automated Policy Enforcement: Uses a policy-as-code engine that intercepts data access requests and validates them against the asset's metadata classification.
- Anonymization Pipeline: Integrates k-anonymity and differential privacy noise injection at the data ingestion layer to sanitize datasets before they reach training clusters.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: Meta Engineering Blog ↗