☁️AWS Machine Learning Blog•Freshcollected in 73m
Build interactive PDF text extraction from Amazon S3
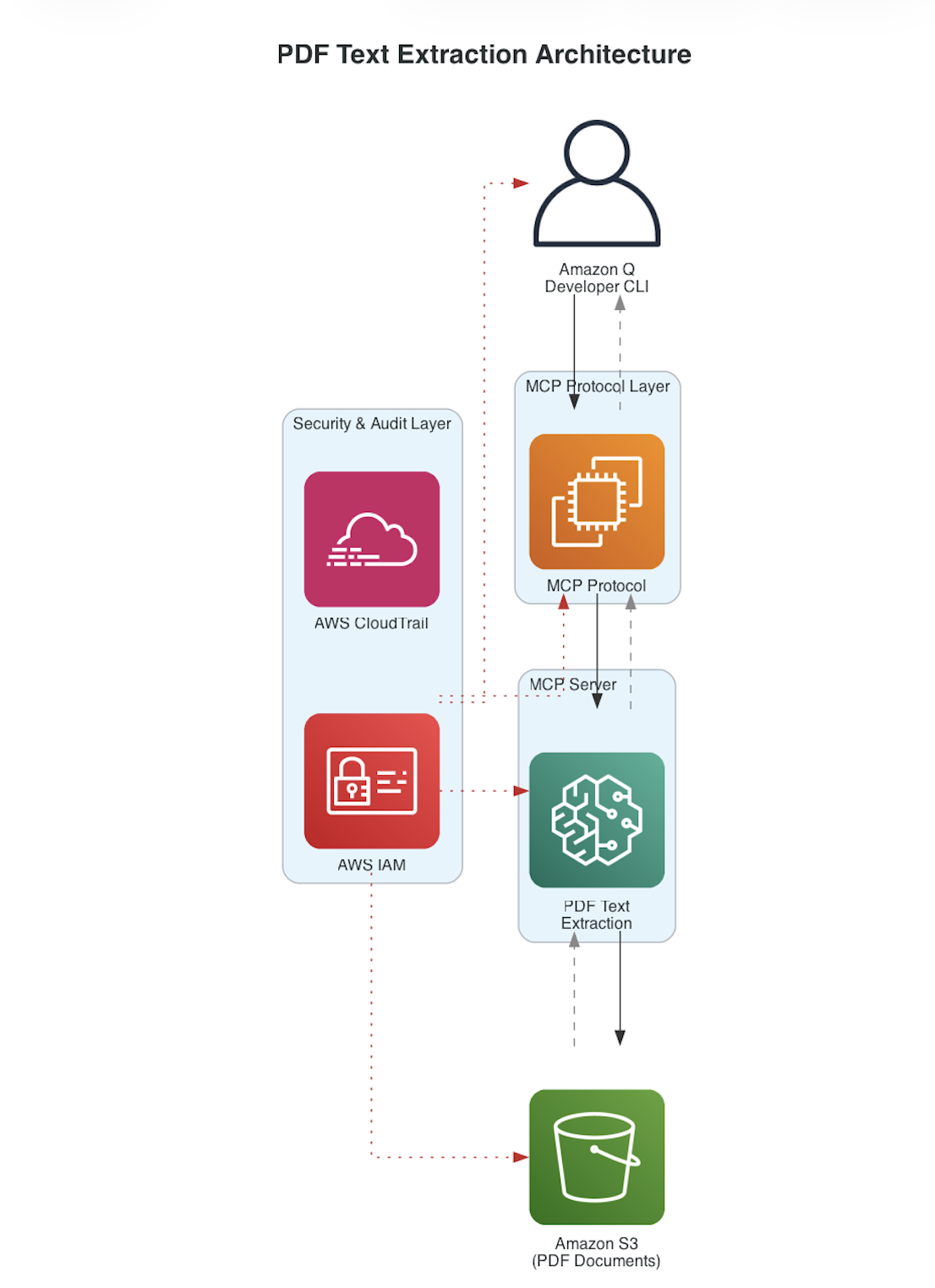
💡Learn to build custom PDF extraction pipelines and compare them against Amazon Textract for your specific workload.
⚡ 30-Second TL;DR
What Changed
Implement real-time PDF text extraction from S3 buckets
Why It Matters
Helps developers optimize document processing workflows by choosing between managed services and custom implementations.
What To Do Next
Evaluate your document processing latency requirements to decide if Amazon Textract is more cost-effective than a custom server.
Who should care:Developers & AI Engineers
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •Amazon Textract now supports native integration with Amazon EventBridge, allowing for event-driven architectures that trigger extraction workflows immediately upon S3 object creation.
- •Recent updates to Amazon Textract include 'Query' features that allow users to extract specific data points (e.g., 'Total Amount') without needing complex regex or post-processing logic.
- •The use of Amazon S3 Select can be combined with Textract workflows to filter large datasets before extraction, significantly reducing costs by minimizing the number of pages processed.
- •AWS has introduced 'Human in the Loop' (HITL) capabilities via Amazon Augmented AI (A2I) to handle low-confidence Textract predictions, ensuring high accuracy for critical document processing.
- •Integration with AWS Glue and Amazon Athena allows for the direct querying of extracted PDF data using standard SQL, bypassing the need for custom database ingestion pipelines.
📊 Competitor Analysis▸ Show
| Feature | Amazon Textract | Google Cloud Document AI | Azure AI Document Intelligence |
|---|---|---|---|
| Core Strength | Deep AWS ecosystem integration | Superior handwriting/OCR accuracy | Enterprise-grade form extraction |
| Pricing Model | Pay-per-page (tiered) | Pay-per-page (tiered) | Pay-per-page (tiered) |
| Latency | Low (Real-time/Async) | Low (Real-time/Async) | Low (Real-time/Async) |
| Customization | High (via Queries/Adapters) | High (via Custom Extractors) | High (via Custom Models) |
🛠️ Technical Deep Dive
- Architecture utilizes Amazon S3 Event Notifications to trigger AWS Lambda functions for asynchronous processing.
- Textract utilizes deep learning models to identify document structure, including tables, forms, and key-value pairs without manual template creation.
- Implementation often involves the use of Amazon SQS to manage message queuing between S3 triggers and the Textract API to handle high-volume document bursts.
- Data persistence is typically handled by storing extracted JSON output in Amazon DynamoDB for rapid retrieval in interactive query systems.
- Security is enforced through IAM roles and S3 bucket policies, with data encryption at rest using AWS KMS.
🔮 Future ImplicationsAI analysis grounded in cited sources
Generative AI will replace traditional template-based extraction.
The shift toward Large Language Models (LLMs) integrated with Textract allows for semantic understanding of documents rather than relying on rigid coordinate-based extraction.
Edge-based document processing will become standard.
As AWS continues to expand its edge computing capabilities, local processing of sensitive documents will reduce latency and data transfer costs for enterprise clients.
⏳ Timeline
2019-05
Amazon Textract is officially launched at AWS re:Invent.
2020-08
Introduction of Amazon Augmented AI (A2I) integration for human review.
2021-12
Launch of Textract Queries to extract specific data without custom code.
2023-04
Expansion of Textract to support complex document analysis including multi-page tables.
2025-02
Integration of generative AI capabilities to summarize and analyze extracted document content.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗