Build a protein research copilot with Amazon Bedrock AgentCore
💡Learn how to combine vector search and LLM summarization to build domain-specific research agents on AWS.
⚡ 30-Second TL;DR
What Changed
Implement natural language query parsing to extract structured search parameters.
Why It Matters
This approach provides a blueprint for domain-specific RAG applications in life sciences. It significantly reduces the time researchers spend manually parsing large protein databases.
What To Do Next
Review the Amazon Bedrock AgentCore documentation to implement a custom research agent for your specific domain data.
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
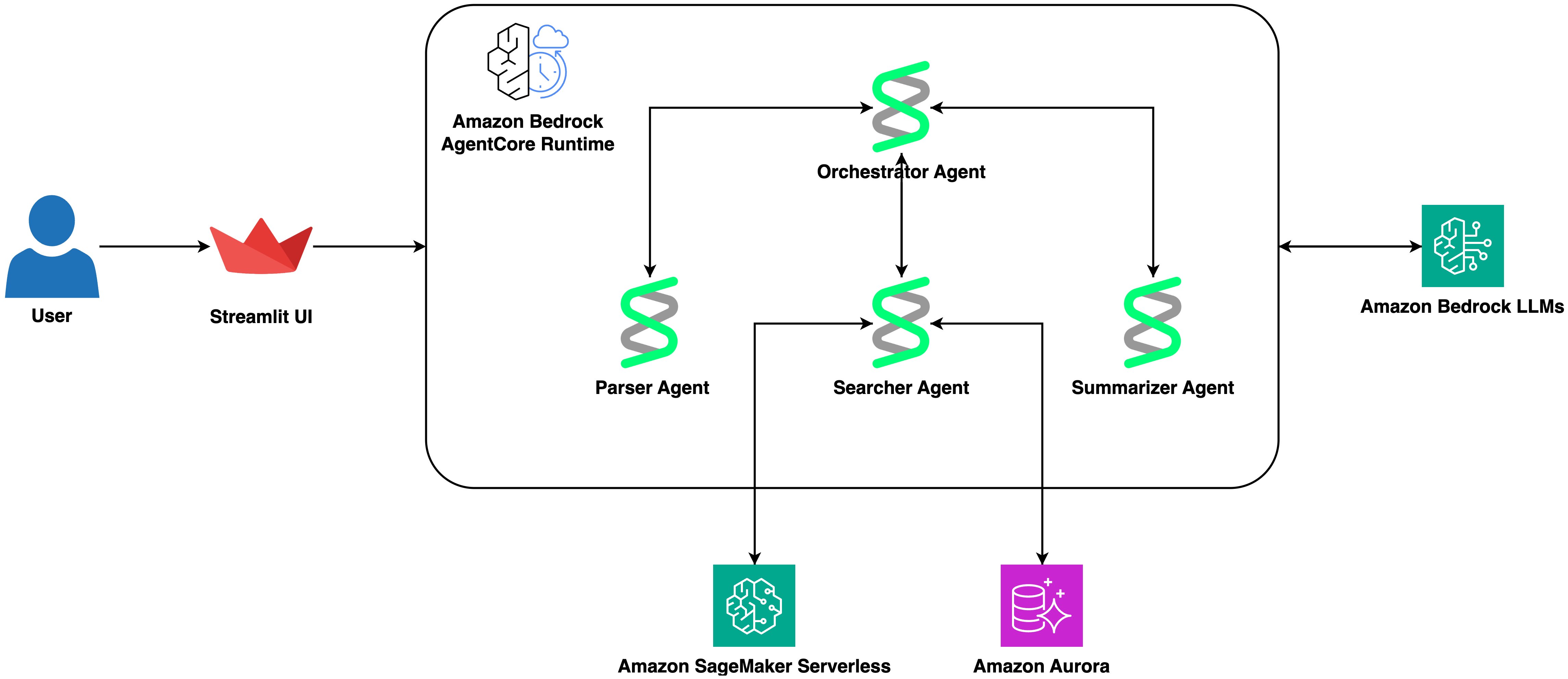
- •Amazon Bedrock AgentCore leverages a modular architecture that separates orchestration logic from domain-specific protein folding or binding affinity prediction tools.
- •The implementation utilizes Amazon OpenSearch Serverless with vector engine capabilities to handle high-dimensional protein embedding spaces efficiently.
- •Integration with AWS HealthOmics allows the copilot to ingest and query proprietary genomic and proteomic datasets alongside public databases like UniProt.
- •The system employs a ReAct (Reasoning and Acting) prompting strategy to enable the agent to iteratively refine search queries based on intermediate retrieval results.
- •Security and compliance features are baked into the agent workflow to ensure adherence to HIPAA and other data privacy standards when processing sensitive biological research data.
📊 Competitor Analysis▸ Show
| Feature | Amazon Bedrock AgentCore | Google Cloud Vertex AI Agent Builder | NVIDIA BioNeMo |
|---|---|---|---|
| Primary Focus | Enterprise Agent Orchestration | Managed Generative AI Apps | Specialized Drug Discovery Models |
| Pricing | Pay-per-token/invocation | Pay-per-query/compute | Tiered SaaS/Cloud subscription |
| Benchmarks | High integration with AWS ecosystem | Strong multimodal capabilities | Industry-leading protein folding speed |
🛠️ Technical Deep Dive
- Architecture: Uses a multi-agent framework where a central orchestrator manages sub-agents for query parsing, vector retrieval, and summarization.
- Embedding Models: Supports integration with ESM-2 (Evolutionary Scale Modeling) and other protein language models for generating vector representations.
- Data Pipeline: Utilizes AWS Glue for ETL processes to convert raw PDB (Protein Data Bank) files into searchable vector embeddings.
- Context Window: Leverages Bedrock's support for large context windows to maintain state across complex, multi-step scientific literature reviews.
- Tooling: Employs LangChain or LlamaIndex abstractions within the Bedrock Agent framework to facilitate external API calls to scientific databases.
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates

AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗